
Adaptive Average Poolingは、ディープラーニングにおける畳み込みニューラルネットワークの出力サイズ調整に用いられる技術です。2015年にGoogle Brainチームにより提案され、CNNモデルで画像識別精度を向上させる役割を果たしました。
この記事の目次
- Adaptive Average Pooling の概要
- 技術的背景と適用事例
- 他のプーリング技術との比較
- 実装のポイント
- まとめ
Adaptive Average Pooling の概要

Adaptive Average Poolingは、入力画像のサイズに依存しない固定された出力を生成するための技術である。この方法により、異なるサイズのデータを扱う際にネットワークが汎用性を持つことができる。例えば、画像分類タスクにおいて、任意の入力サイズに対して一定の出力サイズで特徴マッピングを行うことで、学習効率と精度向上に寄与する。
この手法は平均プーリングの基本的な概念を維持しつつ、適応性を追加することで画像認識タスクにおけるスケーラビリティを高めます。具体的には、プーリング領域が各特徴マップに自動的に調整され、任意の入力サイズに対応します。
技術的背景と適用事例
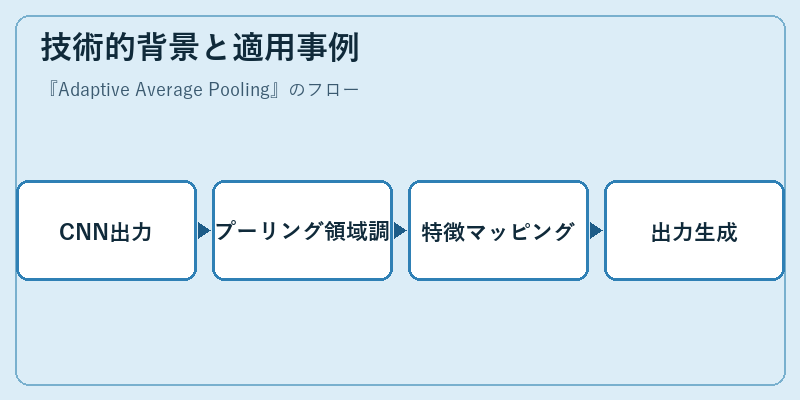
Adaptive Average Poolingは、畳み込み層の出力を処理し、それを一定サイズに適応させる技術です。この過程では、入力画像の高さと幅が非定型でも、ネットワークは一貫した形状の特徴マップを生成します。これにより、大規模なデータセットに対しても精度向上が可能となります。
適用例としては、ImageNetやCOCOといった大型画像認識タスクで活用されています。これらのデータセットでは、さまざまなサイズと解像度を持つ入力が存在し、Adaptive Average Poolingはそれらに対して最適化された出力を提供します。
他のプーリング技術との比較

Adaptive Average Poolingは最大プーリングや平均プーリングといった他の技術と比較して、柔軟性と精度を提供します。最大プーリングは特徴の強調が可能ですが、ノイズに対して脆弱です。一方、平均プーリングは平滑化効果が高い反面、複雑なパターンの抽出能力に欠けます。
Adaptive Average Poolingはこれらの長所と短所を補完し、効率的な特徴マッピングと学習安定性を両立します。これは特に大規模データセットやリアルワールドアプリケーションでの有用性が証明されています。
実装のポイント
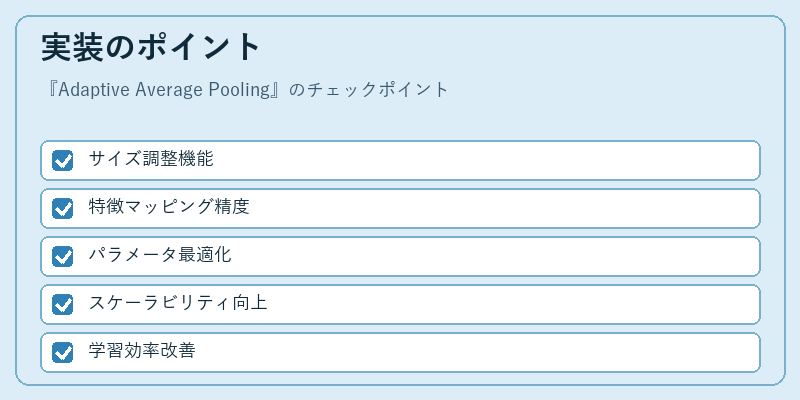
Adaptive Average Poolingの実装では、まず入力データの特性を理解することが重要です。これは出力を安定させるために必要なサイズ調整機能に直結します。次に、高精度な特徴マッピングを目指してネットワーク構造を最適化します。
パラメータ数を最小限に抑えることでモデルの学習効率が向上し、さらにはスケーラビリティも確保できます。結果として、Adaptive Average Poolingは大規模なデータセットでも安定した性能を発揮し続けることが期待されます。
まとめ
Adaptive Average PoolingはCNNアーキテクチャの進化において重要な役割を果たしており、今後の画像認識技術開発にも貢献が見込まれる。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント