
2006年に創設され、現在でも大規模データ分析に欠かせない存在であるApache Hadoop。HDFSとMapReduceのコンセプトを基盤とし、大量かつ複雑なデータセットに対する並列処理能力で脚光を浴びている。
この記事の目次
- 分散ストレージと計算
- Apache Hadoopの機能
- アーキテクチャの流れ
- 競合との比較
- まとめ
分散ストレージと計算
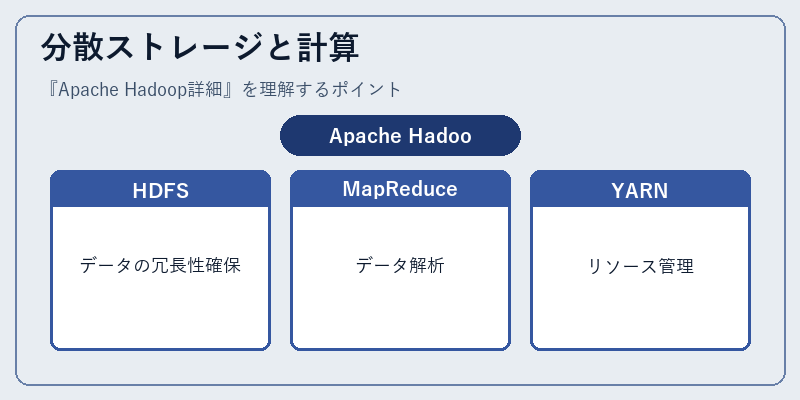
Apache Hadoopは、大規模な分散ストレージと計算能力を実現するフレームワークである。この機能は、Hadoop Distributed File System(HDFS)によるデータの冗長性確保とMapReduceによって処理が並列化されることで可能となる。
例えば、大量のウェブログデータを解析する場合、HDFSではこれらのファイルが多数のノードに分散され、それぞれのノードで独自の計算が行われる。これにより、スケーラビリティと信頼性が高いデータ処理環境が構築される。
Apache Hadoopの機能

Hadoopは、大規模なデータセットを扱うために必要な機能を提供する。これらの機能により、大量の非構造化データを容易に解析することが可能になる。
具体的には、ユーザーはデータを分割して分散的に保存し、必要に応じて迅速かつ効率的に処理できるようになる。これにより、企業がビッグデータ戦略の一環としてHadoopを利用する機会が増えている。
アーキテクチャの流れ
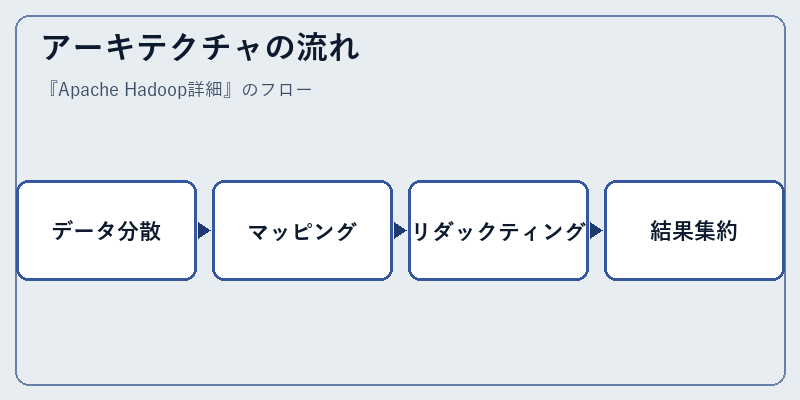
Apache Hadoopの処理フローは、まずデータがHDFSに分散保存されるところから始まる。次に、MapReduceジョブにより各ノード上でデータが並列に解析され、最後に全ての結果が統合されて最終的な出力となる。
このプロセスを通じて、大量の非構造化データを効率的に処理するためのフレームワークとしてHadoopは評価されている。
競合との比較
Apache Hadoopと類似の役割を持つSparkとの比較は、両者のアプローチや機能の違いを理解する上で重要である。Hadoopは主に分散ストレージと並列計算フレームワークとして知られる一方で、Sparkはその上位互換性を持ちつつ高速な処理性能を提供している。
このように両者には類似点が多いが、具体的なユースケースによって最適な選択肢が異なる。たとえば大量の非構造化データに対する初回解析ではHadoopが有効である一方で、頻繁に実行される複雑な計算要求に対してはSparkの方が適している。
まとめ
Apache Hadoopは大規模データ処理における重要な基盤技術として位置づけられ、今後のビッグデータ分析においてもその役割を果たし続けることだろう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント