
Apache Spark SQLは、Big Data分析ツールとして広く採用されているSparkプロジェクトに含まれる。2014年に登場し、SQLクエリを直接サポートすることで差別化を図った。現在では高度なデータ統合やリアルタイム処理機能が追加され、企業のデジタルトランスフォーメーションに欠かせない存在となっている。
この記事の目次
- Spark SQLとは
- 技術的背景
- 機能と特性
- Spark SQLの利点と課題
- まとめ
Spark SQLとは
Spark SQLは、Apache Sparkプロジェクトで開発された、ビッグデータ処理向けの重要なフレームワークです。このツールはHiveQLやSQLとの互換性を提供し、大量のデータ上での高度なクエリが可能にします。
例えば、複数のデータソースからの統合を行う際、Spark SQLは異なる形式のデータを統一的に処理する能力を示し、これは企業の意思決定プロセスを効率化するために不可欠です。
技術的背景
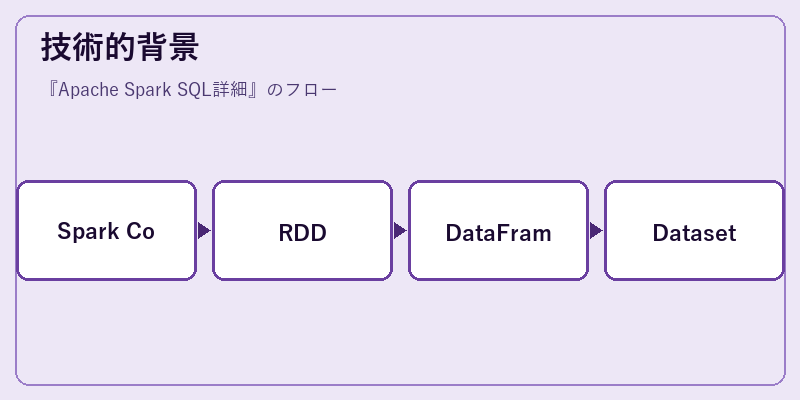
Apache Spark SQLは、Spark Core API上で構築され、Resilient Distributed Datasets (RDD) の概念を拡張します。これによりデータフレームとデータセットの抽象化が可能になります。
これらの高度な抽象化は、開発者がSQL文だけでなく、モダンな言語APIで操作を行えるようにし、PythonやScalaといったプログラミング環境との親和性も高めています。
機能と特性

Apache Spark SQLは、独自のCatalyst SQL解析ツールとTungsten最適化エンジンを搭載し、データ処理のパフォーマンス向上に貢献しています。これにより、大規模なデータセットでも高速なクエリ応答が可能となります。
これらの機能は他のビッグデータツールと比較して際立っており、特にHadoop Hiveからの移行を計画している企業にとって魅力的です。
Spark SQLの利点と課題
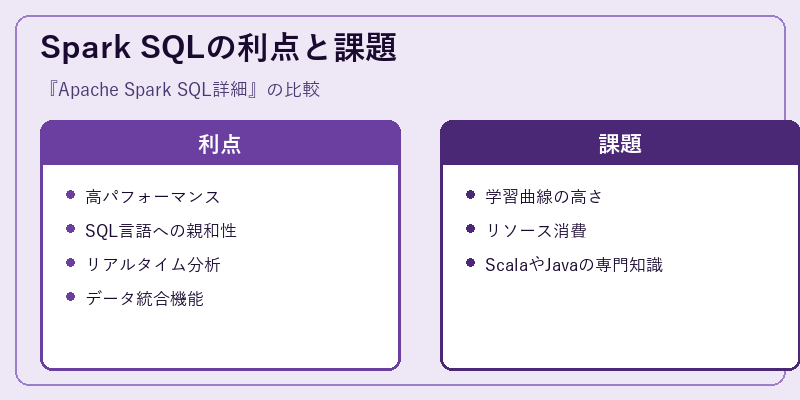
Spark SQLはその高いパフォーマンスと柔軟なSQLクエリサポートにより、大規模なデータ分析プロジェクトで広く採用されています。しかし、これらの特性を最大限に引き出すためには専門的な技術スキルが必要です。
また、大きなデータセットや複雑な処理では大量のシステムリソースを消費する可能性があります。この点は導入時の注意が必要となります。
まとめ
Apache Spark SQLは、高度なビッグデータ分析に必要な機能と柔軟性を兼ね備えたツールであり、その進化は今後も注目されるでしょう。ただし、適切な管理と最適化が成功の鍵となります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント