
AutoTokenizerは、自然言語処理における重要なテクノロジーであり、人間が生成した文章を機械学習モデルに適切な形で入力するための前処理として使用されます。その起源と進化、そして現代における役割を概観します。
この記事の目次
- AutoTokenizerとは
- AutoTokenizerの発展
- 仕組みと機能
- AutoTokenizerと他の前処理との比較
- まとめ
AutoTokenizerとは
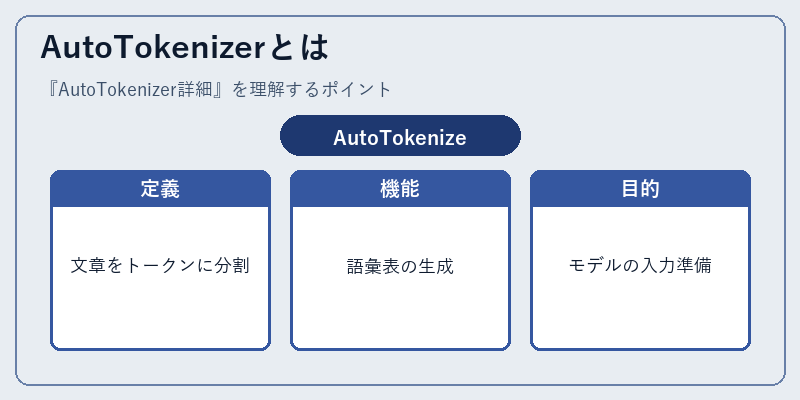
AutoTokenizerは、自然言語処理において重要な役割を果たします。これは機械学習モデルが理解しやすい形で文章を扱うためのツールであり、
具体的にはトークン化、または文字列から意味的な単位への分割を行います。例えば、「こんにちは、世界」というフレーズは「こんにちは」、コンマ、スペース、そして「世界」という4つのトークンに分解されます。
AutoTokenizerの発展
AutoTokenizerは、過去数年間で急速な進化を遂げました。これは、その効率と柔軟性が多くのアプリケーションに広く採用されたためです。
最近では、新しく登場したTransformerアーキテクチャとの統合により、AutoTokenizerは高度な処理能力を持つようになりました。これによって、より複雑な文脈理解や大規模データセットの扱いが可能となっています。
仕組みと機能
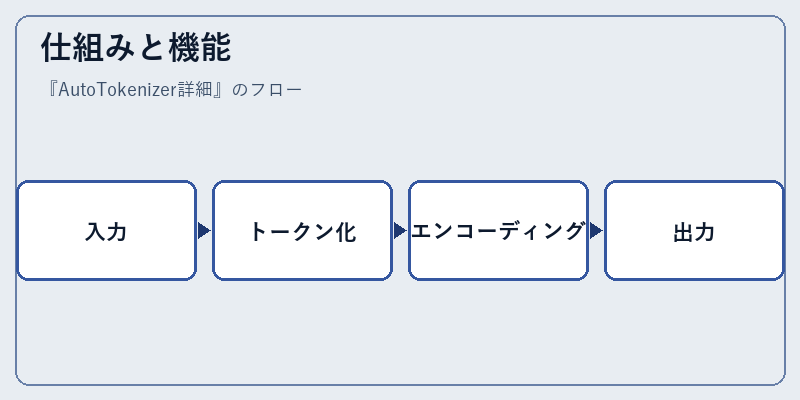
AutoTokenizerは、文章を処理する特定の手順に従って動作します。これは、ユーザーが提供したテキストから開始し、最後にはモデル用の適切な形式で表現を作り出します。
たとえば、英語の文章「How are you today?」はまずトークン化され、「How」、「are」、「you」、「today」、「?」という形に分割されます。次にこのリストが数値に変換され、モデルの入力として送られます。
AutoTokenizerと他の前処理との比較

AutoTokenizerは、他のトークン化ツールと比較して優れた性能を発揮します。これは、その自動化機能や高い柔軟性によるものです。
従来型の前処理アルゴリズムとは異なり、AutoTokenizerは機械学習モデルとの連携が容易で、大規模なデータセットに対しても効率的に動作するため、より高度な応用が可能となります。
まとめ
AutoTokenizerの多様な機能と進化を理解することは、自然言語処理における最新技術を活用する上で欠かせないステップです。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント