
cl-tohokuが開発した日本語BERTは、従来の外国語モデルに比べて優れた性能を示す。この記事では、その特徴や進化の過程、実際の応用事例について詳しく解説します。
この記事の目次
- cl-tohokuによる開発経緯
- 日本語BERTの仕組み
- 他の自然言語モデルとの比較
- 実用化と今後の展望
- まとめ
cl-tohokuによる開発経緯
cl-tohokuは、日本語特有の表現を考慮したBERTを開発しました。その背景には、英語や中国語などの外国語で成功したモデルがそのまま適用できない問題がありました。
具体的には、丁寧語や敬語といった文化特有の要素に対応する必要性があります。cl-tohokuはこの課題に取り組み、日本語に最適化されたモデルを提供しました。
日本語BERTの仕組み
cl-tohokuによる日本語BERTは、文脈理解や誤り訂正といった機能を強化しています。これらの技術により、より精密な自然言語処理が可能になります。
さらに、多様な学習データを取り入れることで、広範囲な応用事例に対応できるようになり、パフォーマンスの向上につなげています。
他の自然言語モデルとの比較
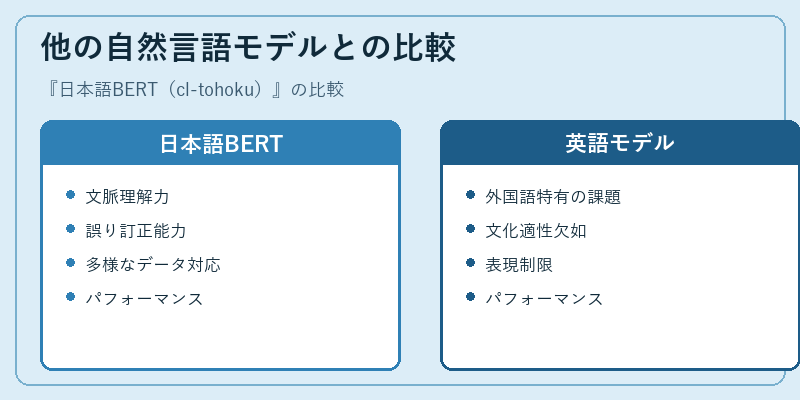
日本語BERTは、他の自然言語モデルと比較して、文脈理解力や誤り訂正能力が優れています。これにより、より正確な応答を提供することができます。
一方で、英語モデルでは文化特有の表現に対応しきれない場合が多い。日本語BERTはこの問題点を改善し、独自のアプローチで日本の自然言語処理を向上させています。
実用化と今後の展望
日本語BERTは、開発から迅速にテストを行い、実際に様々な場面で活用されています。その効果には高い評価が寄せられています。
しかし、さらなる改善のためには継続的な研究と実装が必要です。今後もcl-tohokuはこの技術を進化させ、より豊かな自然言語処理の世界を目指しています。
まとめ
cl-tohokuによる日本語BERTは、文脈理解や誤り訂正能力が高く、多様なデータに対応できるため、実用的な自然言語処理技術として注目を集めている。今後の展開にも期待したい
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント