
19世紀後半にヨハン・ベルヌーイの統計理論を基盤とし、20世紀後半にエドワード・ジェファリーズらによって発展したベイズ推定法。現代では主にテキスト分析や自然言語処理において、単語頻度からクラス分類を行う簡潔なアルゴリズムとして利用される。
この記事の目次
- ベルヌーイナイーブベイズの定義
- ベルヌーイナイーブベイズの歴史的背景
- ベルヌーイナイーブベイズの特徴
- ベルヌーイナイーブベイズと他の機械学習モデルの比較
- まとめ
ベルヌーイナイーブベイズの定義

ベルヌーイナイーブベイズは、テキストの特徴量である単語の出現頻度を用いて、文書が特定のクラスに属する確率を推定する手法だ。このモデルでは、個々の単語間の依存関係を無視し、各単語が独立しているという仮定(ナイーブな前提)を利用。
具体的には、訓練データから文書が特定クラスに属する確率と、そのクラスにおける各単語の出現確率を計算して分類を行う。単純なモデルゆえに高速処理が可能で、大規模なテキストデータにも適応しやすい。
ベルヌーイナイーブベイズの歴史的背景

ベルヌーイナイーブベイズは、その名の通り17世紀スイス数学家ヨハン・ベルヌーイの統計理論と20世紀半ばに確立されたベイジアン推定法に基づいている。その後、自然言語処理におけるテキスト分類への応用が進み、今日では実践的なアルゴリズムとして広く使用されている。
この手法は、文書が属するクラスとその中に現れる単語の出現頻度を数理モデルで表現することで、新たな文書のカテゴリ分類を行う。その仕組みの簡潔さと計算効率性により、大量のテキストデータに対する高速な処理能力を持つ。
ベルヌーイナイーブベイズの特徴

ベルヌーイナイーブベイズは、単語出現頻度のみを考慮するため計算が非常に効率的だ。しかし、単語の連鎖関係や文脈情報など重要な要素を無視してしまう欠点がある。
一方で、その簡潔さゆえに多くのテキスト分類問題に対応可能であり、大量データに対してリアルタイムでの分類が可能になる。このモデルは、例えばスパムメールフィルタリングやウェブ検索エンジンのリレーバランスなど幅広い用途で活用されている。
ベルヌーイナイーブベイズと他の機械学習モデルの比較
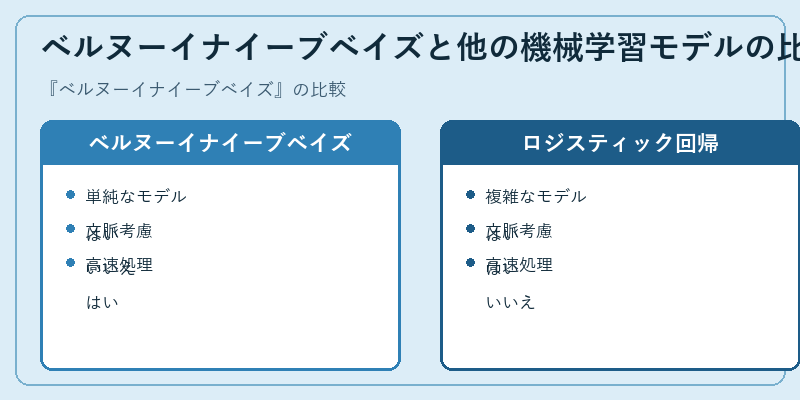
ベルヌーイナイーブベイズと類似の分野で活躍するロジスティック回帰との比較では、前者が単純なモデルを採用することで文脈依存関係を無視し、後者はより詳細な情報を考慮に入れつつ処理速度は遅いという特徴がある。
ベルヌーイナイーブベイズはその簡潔さから大量データの迅速な分類に最適だが、ロジスティック回帰は精度を優先し、より複雑で詳細なモデル構築を行う。両者はそれぞれ異なるニーズや状況において有用性を発揮するだろう。
まとめ
ベルヌーイナイーブベイズはその単純さと効率性からテキスト分類に広く適用される一方、文脈依存関係の無視という欠点も持つ。このモデルを理解し適切に選択することで、最適なデータ処理が可能になる。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント