
2021年に登場したbge-largeは、大量のテキストデータを学習することで高度な自然言語処理能力を持つ。近年では類似のTransformerアーキテクチャに基づくモデルと競い合い、特定の応用領域での強みを探求する動きが活発化しています。
この記事の目次
- bge-largeとは
- bge-largeとTransformer
- bge-largeの内部構造
- bge-largeの応用
- まとめ
bge-largeとは
bge-largeは、大規模なパラメータ数と大量のトレーニングデータを持つことで知られる。これにより、言葉の文脈や意味理解といった複雑なタスクにも対応可能となる。
例えば、ニュース記事から要約を作成する際にはbge-largeが汎用的な知識を活かし効果的だ。一方で特定の業界専門性が必要な場合には微調整を通じて適切に対処できる
bge-largeとTransformer
bge-largeは、Transformerアーキテクチャを基盤とし、特に大規模なパラメータ数や多言語サポートで差別化している。
これらにより、幅広い自然言語処理タスクに対応するだけでなく、特定の分野での高度化も可能にしている。
bge-largeの内部構造
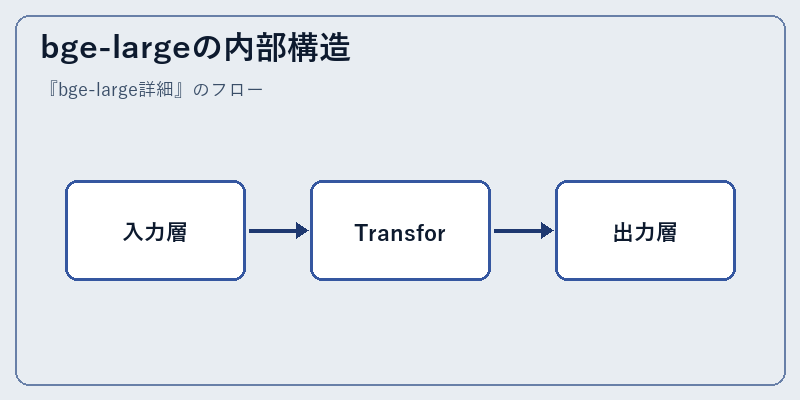
bge-largeは基本的な構造として、順番に入力層からTransformerブロックへと信号を送り、最後に出力層で結果を生成する。
その中でも特筆すべきは、Transformerブロックの数が多く配置されている点。これにより言語理解やタスク対応が高度化し、より精緻な応答が可能になる
bge-largeの応用

bge-largeは、言語翻訳や質問応答など様々な自然言語処理タスクに適している。特に複雑な文脈理解が必要な分野ではその強みが活かされる。
例えば、長大な法律文書から重要な条項を抽出する際にはbge-largeの深い理解力が役立つ。また、感情分析や文章生成でも高い精度で対応可能である
まとめ
bge-largeはその大規模性と汎用性から、さまざまな自然言語処理タスクに対応できる優れたモデルとして評価されている。しかし特定のニーズに合わせた微調整が不可欠な点も念頭においておくべきである
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント