
Blendingは、機械学習とデータサイエンスにおいて複数のモデルを組み合わせて強力な予測モデルを作成するテクニックです。1980年代から研究されてきましたが、近年のデータセット拡大とともに新たな注目を集めています。
目次
この記事の目次
- Blendingとは
- Blendingの仕組み
- Blendingの長所と短所
- BlendingとStackingの違い
- まとめ
Blendingとは
Blendingは、異なる機械学習アルゴリズムから得られた推論結果を融合して最終的な予測を生成する手法です。
具体例としては、ランダムフォレストと勾配ブースティング決定木の結果を線形回帰モデルで結合し、より正確な予測を作り出す方法があります。
Blendingの仕組み
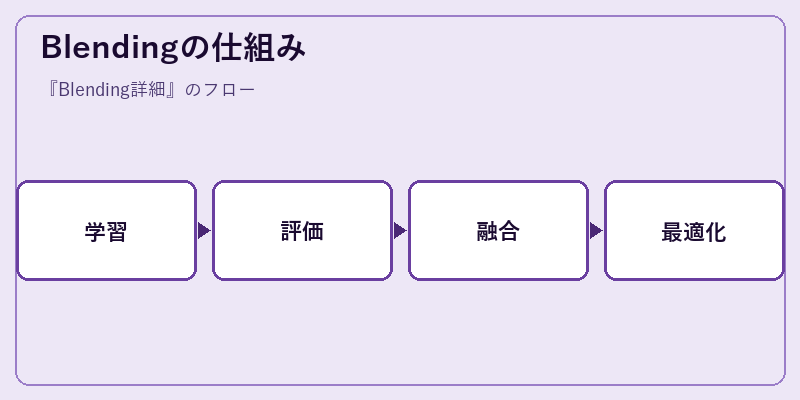
各モデルは個別に学習と評価を行い、その予測結果を別の統合アルゴリズムへ供給します。
このプロセスでは重要なステップが含まれており、精度向上のために反復的最適化を行うことが一般的です。
Blendingの長所と短所

Blendingの利点としては、複数モデル間での予測精度向上と過学習防止が挙げられます。一方で、計算資源やモデル選定に関する課題も存在します。
具体的には、複雑さから来る解釈性の低下や、適切なモデルセットを見つけるための時間と労力を考慮する必要があります。
BlendingとStackingの違い

BlendingとStackingはともに機械学習モデル間での知識統合を目的とするが、技術的には明確な違いがあります。
特にBlendingでは各予測器の出力層で統合を行う一方、Stackingでは中間層からのデータを再び学習させます。
まとめ
Blendingは多様なモデルアーキテクチャを効果的に組み合わせ、予測精度を高める強力なツールです。しかし、その適用には適切な計算リソースと深い知識が求められます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント