
2022年にMetaが開発したBLIP-3は、視覚とテキストの統合に革命をもたらしました。この多機能なモデルは、画像説明やコンテクストに基づく画像の質問応答といった複雑なタスクを手軽に処理します。
この記事の目次
- BLIP-3の特徴
- BLIP-3のアーキテクチャ
- BLIP-3と類似技術
- BLIP-3の実装と研究
- まとめ
BLIP-3の特徴
BLIP-3は、元々の視覚と言語の統合技術に加えて、対話を通じた理解力も高めています。これにより、ユーザーが画像に関する詳細な質問に対してもスムーズに応答します。
具体的には、モデルは以前の会話履歴から文脈を抽出し、それに基づいて適切な回答を作り出します。このような機能は、対話型アプリケーション開発にとって画期的な一歩と言えるでしょう。
BLIP-3のアーキテクチャ
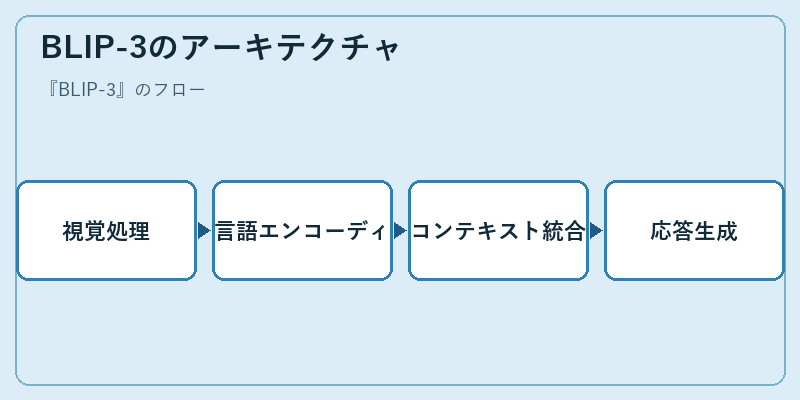
BLIP-3の機能を支えるのは、効率的なマルチモーダルアーキテクチャです。まず視覚情報が解析され、言語データと共にエンコードされます。
その後、コンテキストの情報を統合して最適な応答を探します。この過程は膨大な学習データを基に効率的に実行されるよう高度化されています。
BLIP-3と類似技術
BLIP-3と比較されることが多いCLIPは、画像の分類に特化していますが、対話的な要素には欠けます。これに対してBLIP-3は言語と視覚情報を統合し、対話にも対応します。
また、言語処理モデルとして有名なBERTは、視覚情報に基づく回答生成に不向きです。一方、BLIP-3はこれらを含む複数のタスクに対応可能という点で進化を遂げています。
BLIP-3の実装と研究

BLIP-3の研究は、実用的なシステム開発と基礎科学の双方で進展を遂げています。大規模なデータセットに基づく学習が可能で、さまざまな応用分野にも柔軟に対応できます。
特に文脈理解能力の向上は、画像解析だけでなく対話型インターフェースなどでも大きな利点となります。これらの特長は今後さらなる進化を導く可能性があります。
まとめ
BLIP-3は視覚と言語の統合において新たな地平を開いた一方で、その応用範囲や限界も注目を集めています。今後の研究開発が期待されます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント