
BRIN(Block Range INdex)インデックスは、PostgreSQLが開発した特徴的なインデックス技術で、連続する範囲内でのデータの一貫性を効率的に管理します。大規模なテーブルと特定のデータ型向けに最適化されています。
この記事の目次
- BRINインデックスの定義
- BRINインデックスの仕組み
- BRINインデックスの適用例
- BRINインデックスとB-treeの比較
- まとめ
BRINインデックスの定義
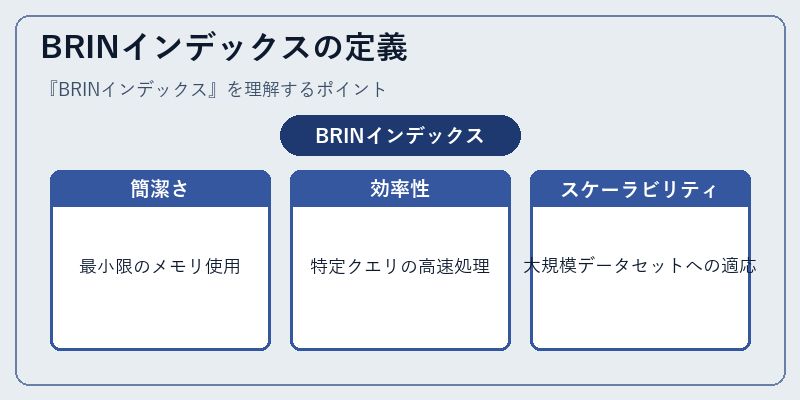
BRINインデックスは、連続するデータ範囲内の値を保存することで、一貫したデータ構造を維持します。これにより、メモリ使用量と管理コストが削減されます。
具体的には、あるテーブルで一定のブロック間隔に従ってインデックスを生成し、その範囲内でのデータの一貫性を確保します。
BRINインデックスの仕組み

データベースシステムが一定の範囲を分析し、その範囲内で存在する最も大きな最小値と最大値を特定します。これらの値は次に、データ範囲内のメタ情報を形成するために使用されます。
これにより、クエリ実行時に効率的なスキップスキャンが可能となり、パフォーマンス向上につながります。
BRINインデックスの適用例

BRINインデックスは、地理的なデータベースや日付範囲の絞り込みなど、連続するデータが関心事となるシナリオに有効です。
その他の一般的な例として、特定のテーブルに対して複数のカラムに対してBRINインデックスを設定し、それぞれのデータ型に対する最適化を行います。
BRINインデックスとB-treeの比較
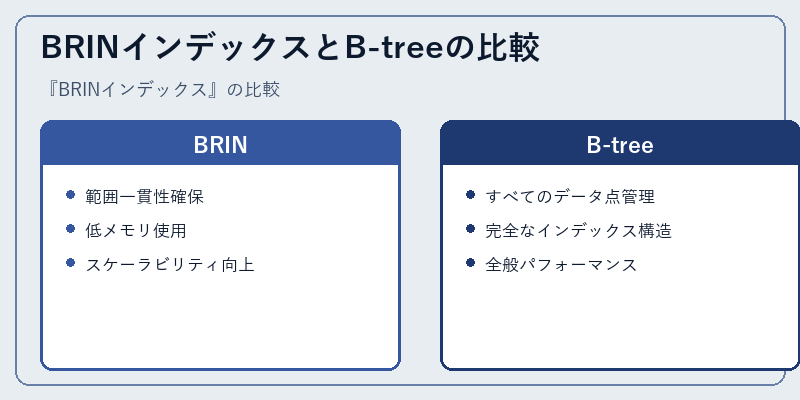
BRINとB-treeは、両方ともクエリ最適化に使用されるが、それぞれ異なるアプローチを採用します。BRINは、連続するデータ範囲内の最小値と最大値のみを使用することで低メモリフットプリントを実現します。
一方で、B-treeはデータベース内で個々のデータ点を管理し、より完全なインデックス構造を提供します。
まとめ
BRINインデックスは大規模なテーブルと特定のデータ型向けに特に効果的なソリューションです。しかし、その適切性は具体的なユースケースによって大きく異なります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント