
Classification and Regression Trees (CART)は1980年代に誕生した、決定木型の機械学習アルゴリズムです。そのシンプルな構造と強力な予測能力から、今日も広く利用され続けています。
この記事の目次
- CARTの定義
- 歴史的背景
- CARTの仕組み
- CARTと他の決定木法との比較
- まとめ
CARTの定義
CARTは、機械学習において重要な位置を占める決定木アルゴリズムです。この手法はデータセットを効率的に分割し、それぞれの分割が目的変数に対する情報増加量を最大化します。その結果、複雑な問題をシンプルな構造に分解することが可能になります。
例えば、ある製品の顧客フィードバックデータに対してCARTを使用すれば、顧客満足度が高いユーザーと低いユーザーを分類できます。これは、年齢やレビュー内容などの属性に基づいて行われるため、企業はより効果的なマーケティング戦略を立てることができます。
歴史的背景

CARTは1980年代にリチャード・ブレマイン(L. Breiman)等の研究者が開発しました。当時から現在まで、その構造と原理が多くの研究者や実務家に受け入れられ続けています。
今日ではRやSパッケージといった統計ソフトウェアだけでなく、Wekaやscikit-learnといった機械学習フレームワークでも使用されています。これらのツールはCARTアルゴリズムを強力な予測機能を持つツールに昇華させました。
CARTの仕組み

CARTは、まず与えられたデータセットを効果的に解析するために、情報増加量に基づいて各ノードでの属性値を比較します。これにより、最も差異が大きい属性に枝分かれを行い、分割が行われます。
このプロセスは再帰的に行われ、最適な決定木構造が得られるまで継続されます。そして最終的には、その結果として生成された木構造を使用して未知のデータに対する予測を行います。
CARTと他の決定木法との比較
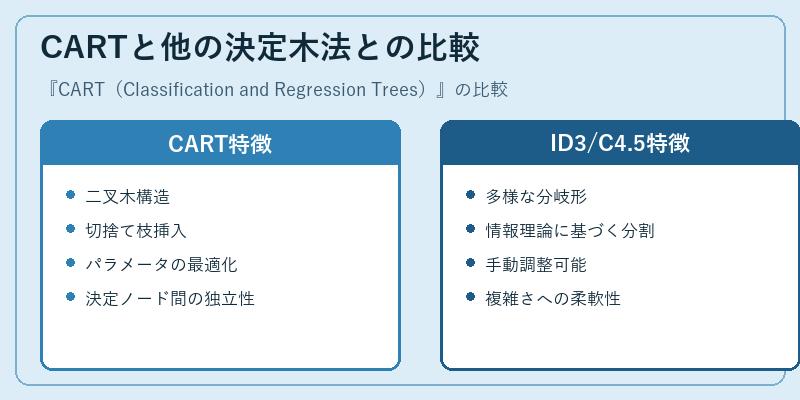
CARTと他の決定木アルゴリズム、例えばID3やC4.5との間には重要な違いがあります。CARTは二叉木構造で、枝分かれのためのパラメータを自動的に最適化しますが、一方でID3やC4.5では多様な分岐形を許容し、情報理論に基づく分割を行うことがあります。
このような異なるアプローチにより、各アルゴリズムは特定の種類の問題に適しています。例えば、大量の高次元データを持つ場合、パラメータ最適化が可能なCARTの方が効果的なことが多いですが、具体的なタスクや利用目的によって最良の選択肢は変わるでしょう。
まとめ
CARTは機械学習における決定木アルゴリズムの中でも特に重要な位置を占めており、その優れた性能と柔軟性により様々なアプリケーションで活用されています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント