
Apache Cassandra のデータモデルは、分散システム向けに設計され、大規模なデータセットを効率的に管理します。この記事ではその歴史から機能まで詳しく掘り下げます。
この記事の目次
- Cassandra データモデルの定義
- Cassandra の開発背景
- データモデルの内部仕組み
- 他のデータベースとの比較
- まとめ
Cassandra データモデルの定義
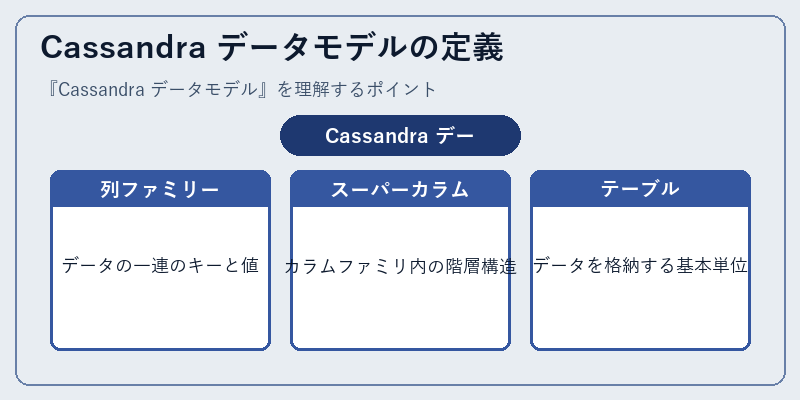
Cassandra のデータモデルは、従来の SQL データベースとは異なり、列ファミリーと呼ばれる概念を利用します。これが一連のキーと値を対応付ける役割を持っています。
さらに、このモデルにはスーパーカラムという構造も含まれており、これはカラムファミリ内の階層構造を作り出す重要な要素です。テーブルはこれらのデータ単位を格納します。
Cassandra の開発背景

Apache Cassandra は Facebook が開発し、後に Apache 社のプロジェクトとなりました。初期段階では、Facebook のメッセージングアプリで大量のデータを管理する必要がありました。
この背景から、Cassandra は分散システム向けに設計され、スケーラビリティと容错性を重視しています。これにより大規模なデータセットの効率的な管理が可能となります。
データモデルの内部仕組み

Cassandra のデータモデルは、それぞれのテーブルが独立したキャッシュを持つ分散ファイルシステムを採用します。これにより、大量のデータを効率的に扱うことが可能となります。
また、このモデルでは複製戦略と障害復旧のメカニズムも強化されており、一貫性と可用性のバランスを取りながら信頼性を維持します。
他のデータベースとの比較
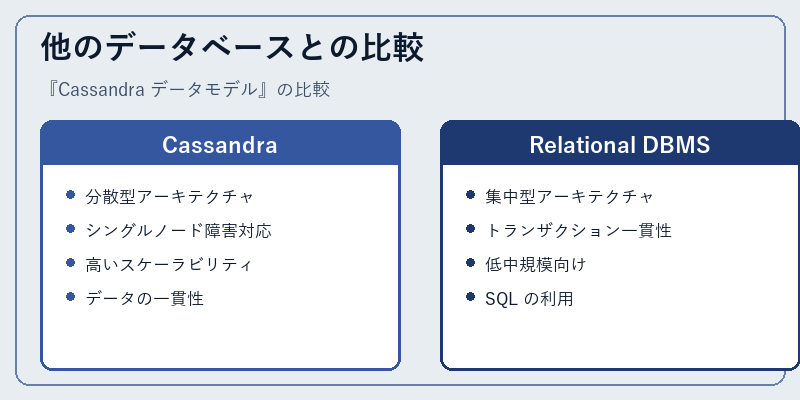
Cassandra は他のデータベースと比べて、分散型のアーキテクチャを採用し、シングルノード障害からも保護される設計となっています。
一方で、Relational DBMS は集中型のアーキテクチャであり、トランザクションの一貫性に優れていますが、大規模なデータセットには向きません。
まとめ
Apache Cassandra のデータモデルは、分散システムにおいて高可用性とスケーラビリティを追求し、大規模アプリケーションの要件に対応します。その特異な構造は他のデータベースとは一線を画しています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント