
cgroups(control groups、シーグループス)は、Linuxカーネルが提供するプロセスグループ単位のリソース制御機構です。2007年にGoogleのエンジニアらによって開発が始まり、CPU、メモリ、I/O、ネットワーク帯域、PID数といったシステムリソースの割り当て・制限・優先度付け・隔離をプロセス階層に対して適用できます。Linux Namespacesと並んで現代のコンテナ技術(Docker、containerd、Podman、Kubernetes)の根幹を成す仕組みであり、systemdによるサービスごとのリソース制御にも利用されています。cgroups v1とv2の二系統があり、近年のディストリビューションでは統一階層のv2が標準となっています。
この記事の目次
- cgroupsを構成する主要なコントローラ
- cgroupsの利用フローと典型的な手順
- cgroupsを活用する際の重要チェック項目
- cgroups v1とv2の構造的な違い
- まとめ
cgroupsを構成する主要なコントローラ
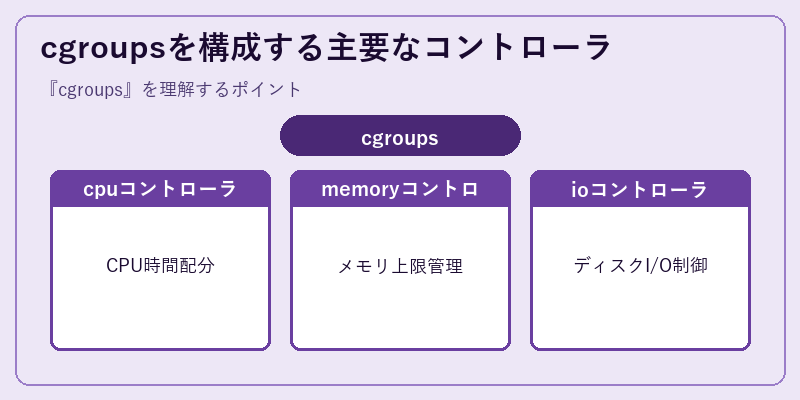
cgroupsはコントローラと呼ばれるサブシステム群で構成されており、それぞれが特定の種類のリソースを管理します。cpuコントローラはCPU時間の重み付け配分(cpu.weight)や絶対値制限(cpu.max)を実現し、複数プロセスが競合する状況下でも公平または優先度に応じた割り当てを可能にします。memoryコントローラはmemory.maxやmemory.highによりメモリ消費の上限を強制し、超過時にはOOM Killerを起動するなどしてシステム全体への悪影響を防ぎます。
ioコントローラはブロックデバイスへの読み書き帯域やIOPSを制限し、特定プロセスがディスクを占有して他の処理を妨げないよう調整します。さらにpidsコントローラはfork爆弾対策としてプロセス数を制限し、cpusetコントローラは特定CPUコアやNUMAノードへの固定実行を実現します。これらコントローラをcgroup階層に応じて柔軟に組み合わせられる点こそが、cgroupsをコンテナ基盤として強力にしている理由です。
cgroupsの利用フローと典型的な手順
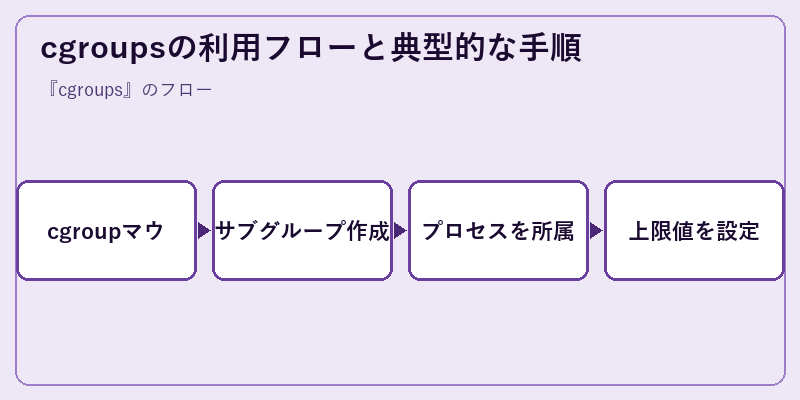
cgroupsを直接操作する場合、まず /sys/fs/cgroup 配下にマウントされた仮想ファイルシステムを確認します。cgroup v2では単一の統一階層が用意され、cgroup.controllersファイルに利用可能なコントローラ一覧が列挙されます。新しい制御グループを作るには mkdir /sys/fs/cgroup/mygroup のようにディレクトリを作成するだけで、対応する制御ファイル群が自動生成されます。
プロセスをそのグループに所属させるには、対象プロセスのPIDを cgroup.procs ファイルに書き込みます。echo $$ > /sys/fs/cgroup/mygroup/cgroup.procs とすれば、現在のシェルとその子プロセスがmygroupに収まります。次に memory.max に容量を、cpu.max に上限を設定すれば、その範囲内でしかリソースを消費できなくなります。実際の運用ではsystemdのスライス/スコープやコンテナランタイムが自動的にcgroupを作成・管理するため、エンジニアが直接ファイルを操作する機会は限られますが、内部挙動を理解しておくことはトラブルシュートに大いに役立ちます。
cgroupsを活用する際の重要チェック項目

cgroupsを利用する上で最初に確認すべきは、システムが v1(複数階層)と v2(統一階層)のどちらで動作しているかです。/sys/fs/cgroup/cgroup.controllers が存在すればv2、controllerごとに別ディレクトリが切られていればv1(あるいはハイブリッド構成)です。コンテナランタイムや監視ツールはどちらの形式で読み書きするかが異なるため、設計初期で確認する必要があります。最近のディストリビューションは概ねv2に統一されつつあります。
メモリ制限はとりわけ慎重な扱いが必要です。memory.maxを超過した場合、デフォルトではcgroup内でOOM Killerが発火し、最もスコア高いプロセスが強制終了されます。アプリケーションによっては予期せぬ停止が業務に大きな影響を及ぼすため、memory.high で段階的にスロットルしたり、監視で早期に検知する仕組みを併用するのが定石です。またI/O制御はファイルシステムやデバイスの種類(block/direct I/O対応状況)によって効き方が変わるため、本番投入前に実機で挙動を検証することが推奨されます。
cgroups v1とv2の構造的な違い
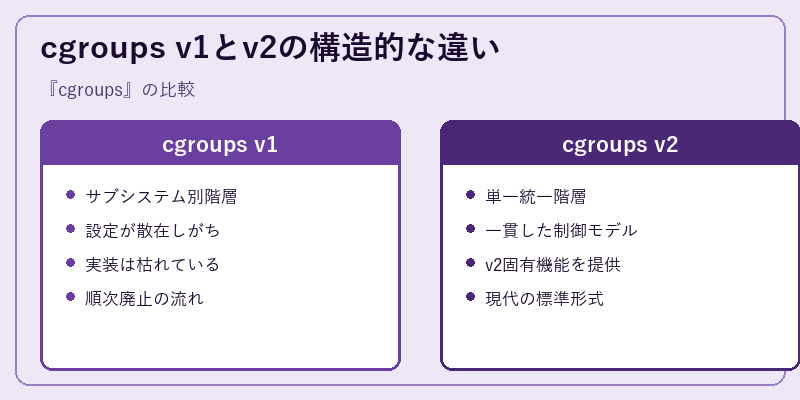
cgroups v1は2007年の登場以来、CPU・メモリ・I/Oといったコントローラごとに別々の階層を構築する設計を採用していました。これは柔軟性が高い反面、同一プロセスが各階層で異なるグループに属する可能性があり、設定の整合性確保が難しいという問題を抱えていました。デバイス制御やfreezerなど多くのコントローラが追加された一方、設計上の制約から実装の不整合や複雑さも目立つようになっていきました。
v2では単一の階層に全コントローラを統合し、各cgroupはすべての制御対象について一貫した親子関係を持つようにモデルが整理されました。これによりcgroup.subtree_controlで子に有効化するコントローラを宣言する仕組みが整い、設定がシンプルかつ予測可能になります。memory.high による穏やかなスロットリング、io.cost や io.latency による高度なI/O制御、PSI(Pressure Stall Information)と連動した負荷指標など、v2でしか使えない機能も多く、コンテナ/システム監視の品質向上に寄与しています。今後はv1廃止の流れがさらに進む見通しです。
まとめ
cgroupsは、Linuxにおけるリソース制御の中核を担うカーネル機構であり、コンテナ技術やサービス管理のあらゆる場面で利用されています。CPU・メモリ・I/Oなどを階層的に制御できる柔軟性は、マルチテナント環境やマイクロサービス基盤に欠かせません。v2への統合により設計が整理され、現代の運用要件に即した機能も拡充しています。クラウドネイティブ時代のLinuxを支える、表からは見えにくいけれど決定的に重要な技術と言えるでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント