
Codex Evaluationは、AIによるコード生成技術を評価するためのフレームワークです。OpenAIが開発したCodex APIを基に、プログラムの品質やパフォーマンスを定量的に測定します。本記事では、Codex Evaluationの特徴、機能、応用範囲について詳細に解説。
この記事の目次
- Codex Evaluationの概要
- Codex Evaluationの実装
- Codex Evaluationの仕組み
- Codex Evaluationと他の手法の比較
- まとめ
Codex Evaluationの概要
Codex Evaluationは、AI生成コードの性能を把握するためのツールです。評価には複数の基準が適用され、品質や効率性に着目します。
さらに、多様なプログラムサンプルから構成されるデータセットに基づき、具体的な結果を導き出します。
Codex Evaluationの実装

Codex Evaluationは、まずAIによるコード生成を行います。その後、評価する指標を定義し、データの取り扱い方や評価ルールを考えます。
また、評価結果の可視化やパフォーマンス解析を行い、改善点を見つけ出します。
Codex Evaluationの仕組み
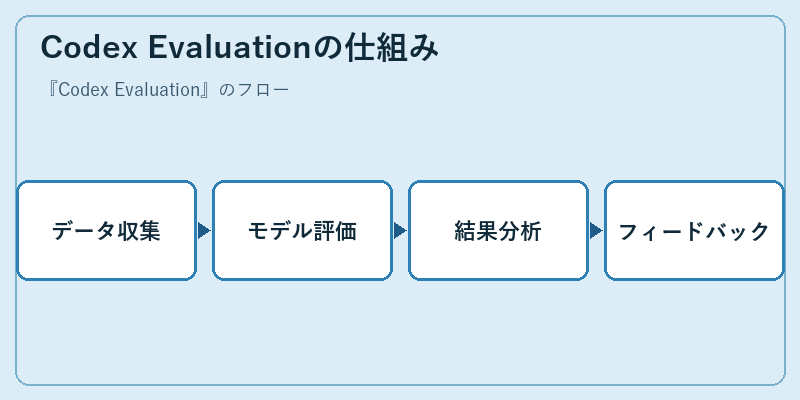
Codex Evaluationでは、初期段階でAIが生成したコードを大量に収集します。次に、これらのコードに対する定量化された評価を行います。
そして、評価結果を分析し、モデルの性能や改善点を見極めます。また、フィードバックプロセスにより継続的な改良を目指す。
Codex Evaluationと他の手法の比較

Codex Evaluationは高度な自然言語処理能力を持ち、複雑なリクエストにも対応できます。また、評価指標も多様性と詳細さを兼ね備えています。
一方で従来の手法では簡易的な入力しか受け付けず、評価指標も限られています。この点でCodex Evaluationは大きな進歩を遂げている。
まとめ
Codex EvaluationはAIコード生成モデルの性能を深く理解し、その改良に向けた道筋を探るための有用なツールです。今後の開発においても重要な役割を果たすと考えられる。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント