
UNIXの時代からある comm コマンドは、2つのソート済みリスト間で共通する行を表示します。データ比較や統合に欠かせないツールであり、現代でもその役割を果たし続けています。
この記事の目次
- commコマンドの基本使用法
- 仕組みと内部構造
- 歴史と進化
- その他の類似コマンドとの比較
- まとめ
commコマンドの基本使用法
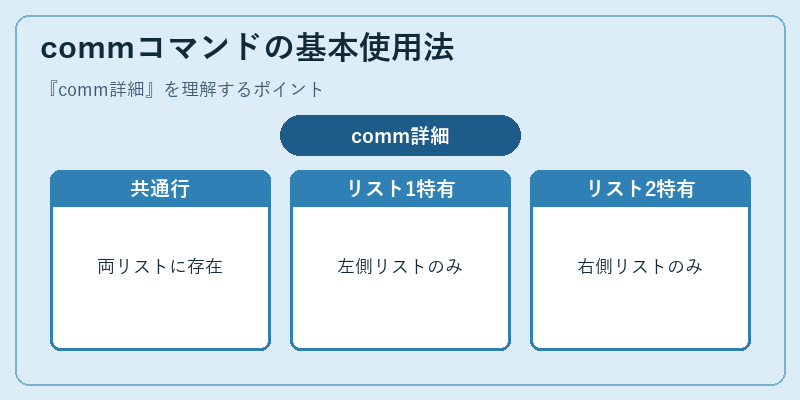
commは3つのオプション(-1、-2、-3)と、比較するファイル名を引数として受け取ります。このコマンドはソートされた入力を要求します。
例えば、ファイルAとBの差分を調べるとき、
comm -3 filea.txt fileb.txt
とすると共通行が出力され、-1または-2オプションを使うことでそれぞれ特有の行が表示されます。
仕組みと内部構造
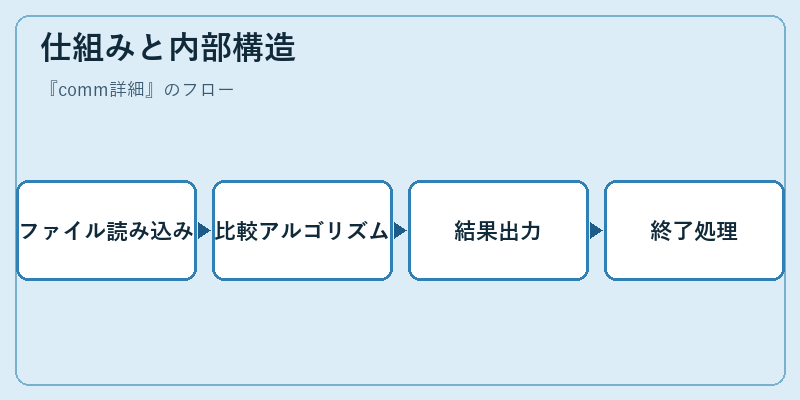
commは、2つのソート済みリストを順に比較し、共通行とそれぞれの特有行を特定します。各ファイルが順序通りであることが前提です。
内部では、特殊な文字列マッチングテクニックを使用して効率的な比較を行います。これにより大きなファイル間でも高速な検索が可能となります。
歴史と進化

commは古くから存在するコマンドであり、初期のUNIXシステムで開発されました。その簡潔さと効率性から長年愛用されてきました。
時間と共に、オプションが追加され機能強化が進みましたが、互換性を維持しながら現代的な機能も取り入れています。POSIX規格へも対応しています。
その他の類似コマンドとの比較

commと類似の機能を持つdiffやgrepは、それぞれ異なるアプローチでデータの比較を提供します。
diffは行レベルの変更点を詳細に報告し、grepは特定パターンのみ抽出します。これらのコマンドとの比較を通じて、commがどのような場合に有用であるかを理解できます。
まとめ
commは、ファイル間の共通行を見つけるための効率的なツールで、Linux環境において重要な役割を果たしています。ソート済みデータでのみ使用可能であり、その特性を理解することでより正確に利用できます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント