
Conditional Variational Autoencoder (Conditional VAE)は、深層学習における画像生成や言語処理などに使われる生成モデルの一種。Variational Autoencoder (VAE)の発展形であり、特定の条件のもとでデータを生成する能力を持つ。
目次
この記事の目次
- Conditional VAEの定義
- Conditional VAEの発展
- Conditional VAEの仕組み
- Conditional VAEと他のモデルの比較
- まとめ
Conditional VAEの定義
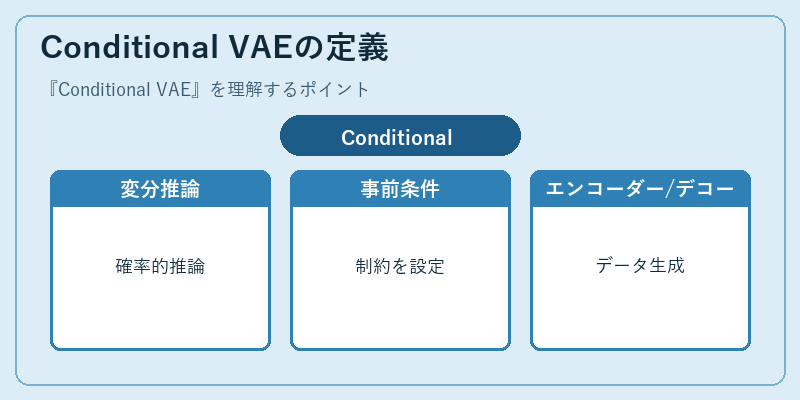
Conditional VAEは、一般的なVAEの仕組みに加えて、特定の条件下でのデータ生成を行う点が特徴です。
例えば、顔画像生成で特定の表情を制御する場合や、文章生成で特定トピックに基づいた文章を作成する際に効果的
Conditional VAEの発展

Conditional VAEは、2016年に研究者が提案して以来、様々な領域で応用範囲を広げてきました。
特に自然言語処理や画像生成、音声合成などでの条件付き生成の精度向上に貢献しています
Conditional VAEの仕組み
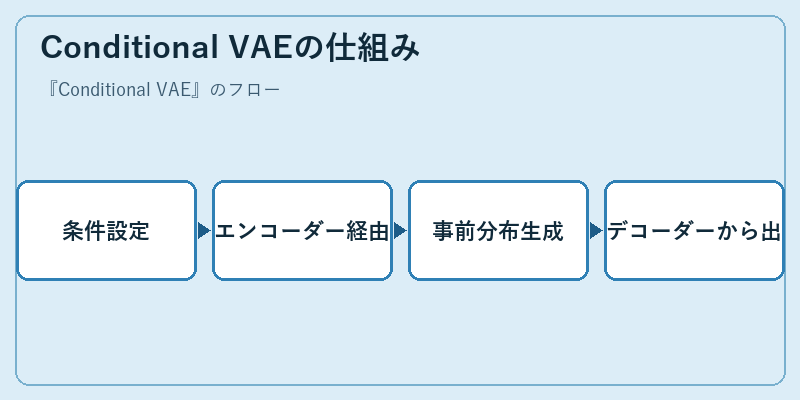
Conditional VAEでは、まず入力データに付加的な情報(条件)を提供します。この情報は生成する結果の方向性を制御します。
次にエンコーダーを通じて潜在変数空間へのマッピングが行われ、そこからデコーダーを通じて具体的な出力を得ます
Conditional VAEと他のモデルの比較
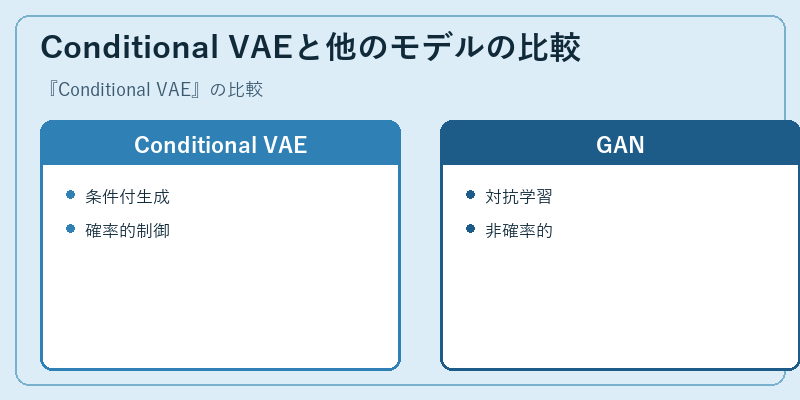
Conditional VAEは、確率モデルに基づくデータ生成を可能にします。一方でGenerative Adversarial Network (GAN)では、生成器と識別器の対立によって生成を行います。
それぞれ特性が異なるため、特定のタスクでは一方がより適している場合があります
まとめ
Conditional VAEは、条件付生成モデルとして幅広い応用が期待される一方で、学習過程や生成結果の安定性など課題も抱えています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント