
Confluent Cloudは、Apache Kafkaプロジェクトを基盤として開発されたリアルタイムデータ処理のためのプラットフォームで、2018年に初めて公開されました。本記事では、その背景や特長、構成要素、競合との比較について詳しく解説します。
この記事の目次
- Confluent Cloudの基本機能
- Confluent Cloudの仕組み
- Confluent Cloudと競合製品の比較
- Confluent Cloudの歴史と発展
- まとめ
Confluent Cloudの基本機能

Confluent Cloudは、Apache Kafkaを基盤にしたサービスとして、主な機能はデータストリームの生成と処理です。これにより、大量かつ高速なデータ移動を可能とします。
また、クラウドネイティブアーキテクチャで構築されているため、セキュリティやスケーラビリティに優れています。具体的には、セキュアな通信環境の確保や手軽なスケーリングといった実践的な利点が挙げられます。
Confluent Cloudの仕組み

Confluent Cloudは、データの生成から最終的な分析までの一連のプロセスを効率化します。このフローは、まずユーザーやアプリケーションがデータを生成し、次にそのデータが一貫性と信頼性を持ったストリームとして処理されます。
その後、Confluent Cloudでは複数のシステムやツールとの連携(統合)を容易に行い、最後にこのプロセスを通じて得られた洞察を分析することでビジネス価値を最大化します。
Confluent Cloudと競合製品の比較
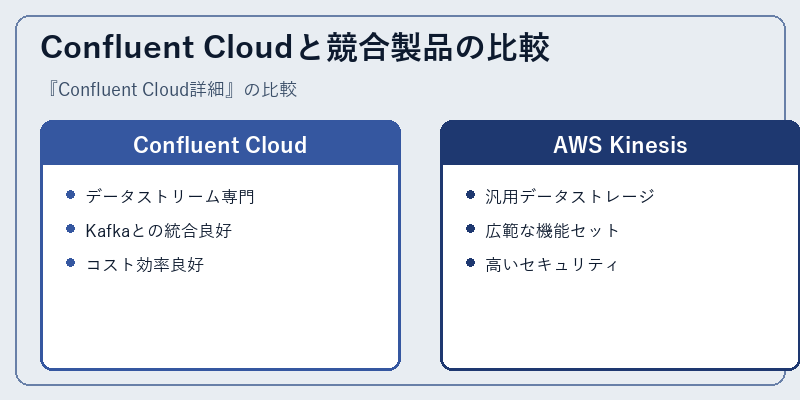
Confluent CloudはApache Kafkaをベースにした特化型のサービスで、データの生成と処理において優れたパフォーマンスを発揮します。これに対してAWS Kinesisは汎用的なデータストレージとして知られています。
ただし、それぞれの製品には長所短所があり、Kafkaとの統合が良好なConfluent Cloudと比較的広範囲な機能を持つAWS Kinesisというように、選択の基準もそのユースケースによります。
Confluent Cloudの歴史と発展
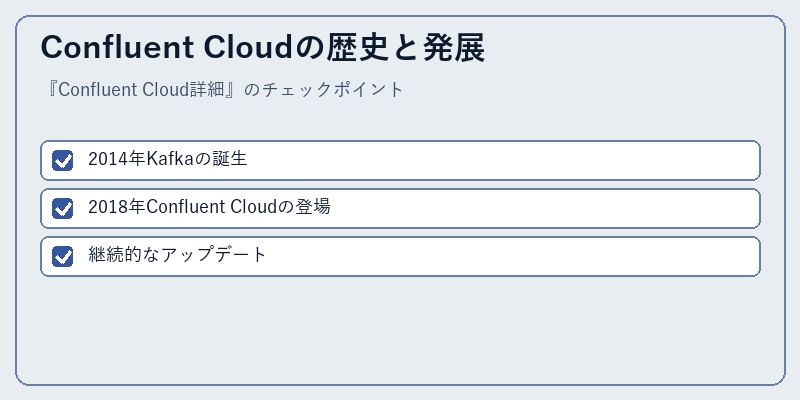
Apache Kafkaは、LinkedInで開発されたデータ連携ツールから始まりました。その後、その機能と柔軟性が認められ、コミュニティ内で急速に普及しました。
この背景のもと、Confluent Cloudは2018年に登場し、Kafkaの進化を支えるクラウドネイティブなプラットフォームとして位置づけられています。今後も機能強化や拡張が期待されます。
まとめ
Confluent Cloudは、Apache Kafkaの高度な機能とクラウドネイティブアーキテクチャを融合させたデータストリーミングプラットフォームであり、リアルタイムでの大量データ処理に強みを持っています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント