
Convolutional Neural Networks(CNN)において重要な役割を果たすConv2D。画像処理や視覚認識など、深層学習分野で広く利用されているが、その詳細な仕組みは理解するのが難しく感じられるだろう。本記事ではConv2Dの歴史から最新動向まで解説する。
この記事の目次
- Conv2Dとは何か
- Conv2Dの歴史と発展
- Conv2Dの実装とパラメータ
- Conv2Dと他の畳み込み操作の比較
- まとめ
Conv2Dとは何か
Conv2Dは深層学習における特定の機能として広く使われている。畳み込み演算を通じて、入力データから重要な特徴を抽出する。この処理が何らかの形で画像のパラメータを解析し、新たな視覚情報への理解へと繋がる。
具体的には、Conv2Dは複数層に渡って畳み込みを行うことで、段階的に抽象的な特徴を抽出する。この過程では、各層ごとに異なるフィルタを適用することで、多様な視点からデータのパターンを見出す。
Conv2Dの歴史と発展

Conv2Dは、1980年代初頭にYann LeCunによって最初のCNNの一環として導入された。その後、Backpropagationアルゴリズムが改良され、深層学習への道を切り開いた。
ここ数年では、Recurrent Neural NetworksやGANsとの統合を通じてさらに進化し続けている。これらの技術は画像生成から音声解析まで幅広い応用で活用されている。
Conv2Dの実装とパラメータ
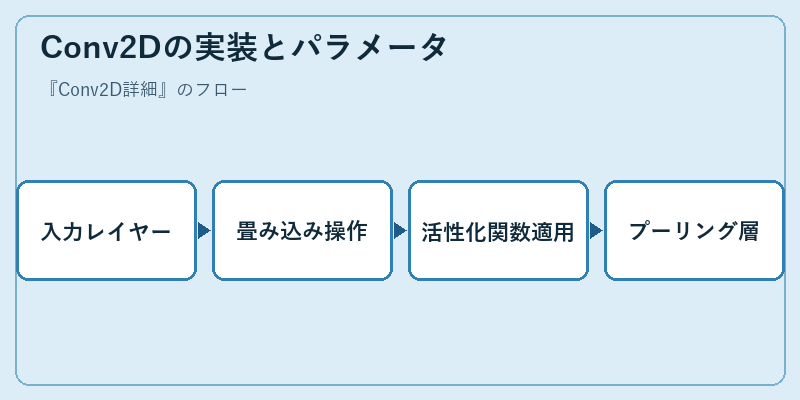
Conv2Dを活用するためには、まず入力データのレイヤーを準備する必要がある。この過程で重要なのは、次にどの種類のフィルタを使用して畳み込みを行うかである。
続いては活性化関数が適用され、プーリング層を通じて非線形な特性が追加される。これらの手順によってConv2Dは深層学習において極めて効率的なデータ解析を可能にする。
Conv2Dと他の畳み込み操作の比較

Conv2DとSeparable Convolutionは、それぞれ異なるアプローチで畳み込み処理を行う。Conv2Dでは複数のフィルタを一度に適用し、チャネル数の増加も容易である。
一方、Separable Convolutionでは、深層学習モデル全体での計算効率を最大化するために、フィルタとチャネル間の操作を分離することでパラメータ数を削減する。
まとめ
Conv2Dは深層学習技術において欠かせない存在であり、その詳細な理解は研究開発や応用における重要な一歩となるだろう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント