
Count-Min Sketch(CMS)は、1990年代後半に開発された確率的データ構造です。大量のデータを効率的に分析するためのアプローチとして生まれたCMSは、頻出要素や大規模な分散システムで重要な役割を果たしています。本記事ではその基本的な概念から最新動向まで詳しく解説します。
この記事の目次
- Count-Min Sketch の仕組み
- CMS の歴史的背景
- CMS の比較対象
- CMS の最新研究
- まとめ
Count-Min Sketch の仕組み

Count-Min Sketch は、入力ストリームから個々のアイテムがどのくらい出現したかをカウントするためのデータ構造です。CMS の内部では、複数のハッシュテーブルが並列に設けられ、それぞれ異なるハッシュ関数でアイテムをキーとしてマッピングします。
この手法は、一般的な配列ベースのカウンターよりも効率的でありながら、一定の確率的な誤差を許容することで実現されています。誤差の程度は、ハッシュテーブルの数とサイズによって制御可能で、これにより必要な精度に応じた構造体を作成できます。
CMS の歴史的背景

Count-Min Sketch の開発は、ビッグデータ時代が到来する前から始まりました。その当初の目的は、大量かつ高速に流れる情報の中から特定のアイテムやパターンを効果的に検出することでした。
この技術はその後、ウェブトラフィック分析やソーシャルメディアでの傾向把握など様々な分野で応用され、現代ではデータストリーム処理における欠かせないツールとして定着しています。
CMS の比較対象
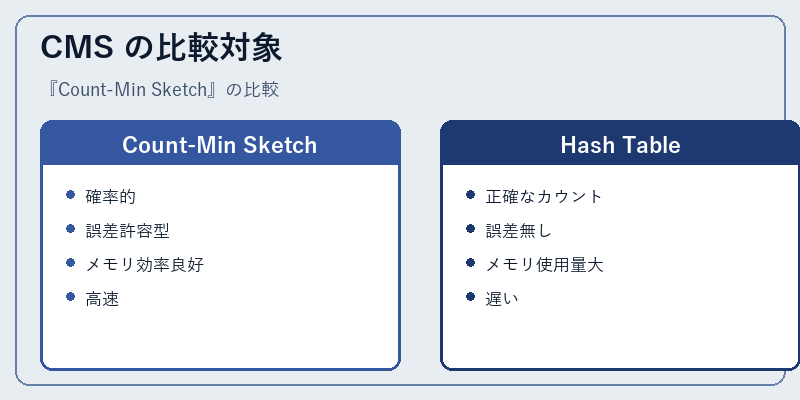
Count-Min Sketch は、その特徴から他のデータ構造と比較して多くの利点があります。ハッシュテーブルと対比すると、CMS は効率的なメモリ管理と高速な処理速度を備えていますが、一方で完全な精度ではなく近似値を提供するという違いもあります。
これはしばしば誤解の元となる点ですが、アプリケーションによっては CMS の特性の方が有用である場合も多くあります。例えば、リアルタイム分析や大量データのサマリ化では、CMS による誤差許容がむしろ大きなアドバンテージとなります。
CMS の最新研究
近年、Count-Min Sketch はより高度な分析や効率的な処理のための新たなアプローチを生み出しました。これらの改良版では、既存の CMS の欠点を補うために様々な手法が提案されています。
例えば、誤差範囲をさらに狭めることで精度向上を目指すものから、複数のストリームに対する統合分析を行うための拡張型 CMS まで、CMS 技術は常に進化し続けています。
まとめ
Count-Min Sketch の原理と応用を学び、実世界の問題解決に活かすことができます。特に大規模データ環境ではその優れた効率性が活きるでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント