
curl -oオプションは、ネットワーク上のリソースをファイルとしてローカルに保存する際に使用されるLinuxコマンドの一部です。1997年にデンマークのソフトウェアエンジニアDaniel Stenbergによって開発され、現在ではWebデータの取得やAPIエンドポイントへのPOSTリクエストなど幅広い用途で利用されています。
この記事の目次
- curl -oの基本的な役割
- オプションの使用例
- curl -oの詳細仕組み
- -oと他のcurlの機能との比較
- まとめ
curl -oの基本的な役割
curl -oは、URLからリソースをダウンロードする際、ローカルファイルシステム上の特定の位置へ保存します。これにより、WebページのHTMLコンテンツや画像といったさまざまな形式のデータが、利用者の意図した場所に適切な名前で格納されます。
例えば、ウェブサイトのRSSフィードをローカルストレージに保存する場合、curl -oはそのような目的に最適です。コマンドライン上で次のように指定すれば、feed.xmlというファイル名でダウンロード可能です。
curl -o feed.xml http://example.com/feed
オプションの使用例

curl -oは、WebページからAPIレスポンスを受信する際など、HTTPプロトコルを使用した様々な通信シナリオで活躍します。たとえば、外部サーバーからのJSONデータを受け取ってローカルファイルとして保存する際には、-oオプションが重要な役割を果たすでしょう。
curl -X GET -H “Accept: application/json” -o data.json https://api.example.com/resource というコマンドはAPIエンドポイントからJSONデータを取得し、data.jsonファイルに保存します。このようにして、一連の処理結果が明確な形で保持され、後続の解析や利用が容易になります
curl -oの詳細仕組み
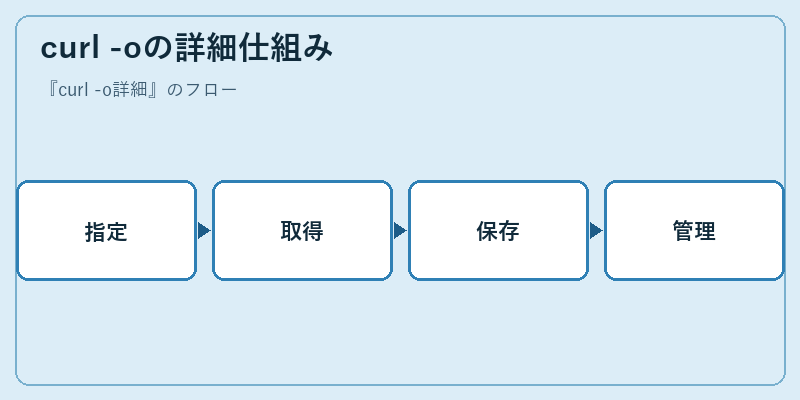
curl -oオプションは、利用者が指定したURLからデータをダウンロードし、その結果をシステム上の任意の場所に保存します。この過程で、HTTPヘッダーの解析やセッション管理など複数のテクニカルな側面が関わってきます。
まず、curlコマンドはユーザーによって指定されたURLへ接続を行い(指定)、リモートサーバーからデータを取得してくる(取得)。その後、ダウンロードしたコンテンツはユーザーが指定したファイルパスに書き込まれる(保存)。このとき、上書き回避のためにバックアップを作成するなどの高度なオプションも利用可能となります(管理)
-oと他のcurlの機能との比較

curl -oは、その機能の側面において、他のオプションやコマンドと比較して独自の役割を果たしています。例えば、標準的なダウンロード操作はファイル名が固定されますが、-oオプションでは任意に変更可能となります。
これにより、単純なデータ取得以外にも、API呼び出し後のレスポンス保存やバッチジョブでの利用など、さまざまなシナリオで柔軟性と効率を高めることができるようになります。
まとめ
curl -oは、ファイルダウンロード時の出力先指定機能を提供し、データ処理の幅広いニーズに応えつつ、システムアーキテクチャにおいて重要な役割を果たしている。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







