
F1 スコアは、データサイエンスや機械学習において混同行列の性能評価を強力に支える指標です。20世紀半ばから発展した概念で、近年では特にクラスアンバランス問題への対応として重宝されています。
目次
この記事の目次
- F1 スコアの定義
- F1 Score の歴史的背景
- F1 スコアの計算方法
- F1 Score と他の性能指標との比較
- まとめ
F1 スコアの定義
混同行列を基にした性能指標の一つとして、F1 スコアは特徴的な性質を持つ。主に精度と recall のバランスを取るために活用される。
たとえば、クラスが極端に偏っているデータセットでは、単純な精度だけでは全体像を捉えるのが難しい場合がある。そのようなケースで F1 スコアは有用である。
F1 Score の歴史的背景

F1 スコアは、情報検索分野で先行的に指標として活用されてきた。初期の段階では、文書ランキングにおける精度と recall のバランスを評価するための手段として脚光を浴びた。
その後、機械学習モデルの性能評価においても広く採用されるようになり、その有用性は多くの研究で示されています。
F1 スコアの計算方法
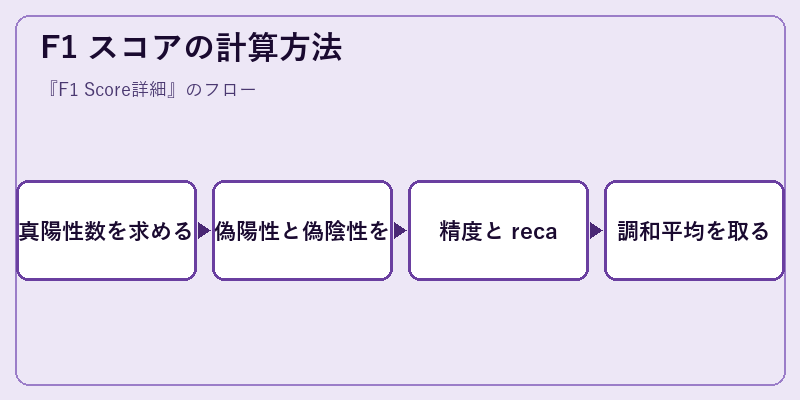
F1 スコアの計算には、まず混同行列から真陽性(TP)、偽陽性(FP)、偽陰性(FN)の値が必要となる。
これらのデータに基づき精度と recall をそれぞれ求め、最後に二つの指標を調和平均で結合することで F1 スコアが得られます。
F1 Score と他の性能指標との比較
F1 スコアは、精度と recall を重視する一方で、ROC 曲線は偽陽性率(FPR)とのバランスを強調します。
両者はそれぞれ独自の特性を持っており、状況や目的により使い分けることが重要となります。
まとめ
F1 スコアの理解と適切な適用を通じて、機械学習モデルの性能評価においてはより精密な指標として機能します。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







