
機械学習における重要なステップである特徴選択とは、データセットから予測に最も有用な変数を選別する技術です。1980年代後半から活用され、近年はAIやビッグデータの進展と共に新たな手法も加わりました。
目次
この記事の目次
- 基本的な目的
- 手法の進化
- 実践上の留意点
- 他の特徴エンジニアリングとの比較
- まとめ
基本的な目的
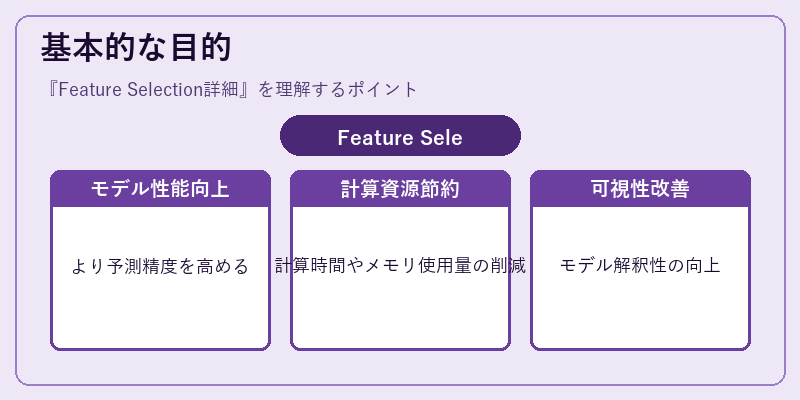
特徴選択は、機械学習における重要な目的である性能向上と計算効率を両立するための技術です。
まず精度面では、不要なノイズや冗長な特徴を取り除くことでモデルの予測精度が改善されます。また、計算資源を節約し、訓練時間も短縮できます。この結果、より複雑なモデル構築にも対応可能となります。
手法の進化
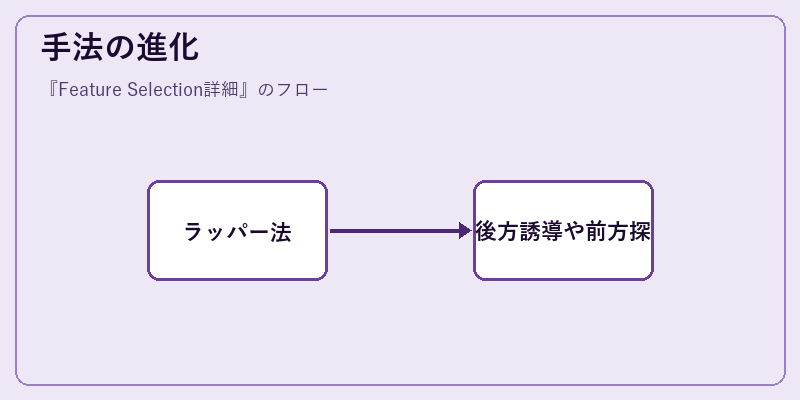
特徴選択は長い歴史を持つ手法で、その技術は時代とともに進化し続けています。
初期のフィルタ法では、統計的な関係性に基づき無駄な変数を排除しました。これに対し、近年普及したラッパー法は、モデル性能自体を直接評価しより優れた結果を導き出します。
実践上の留意点
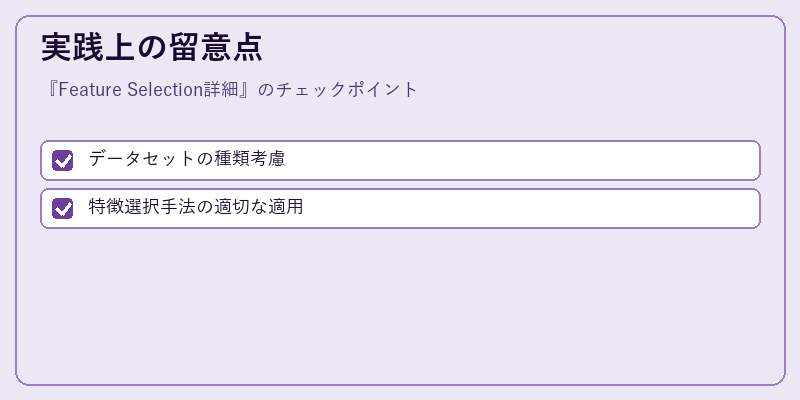
実際のプロジェクトで特徴選択を行う際には、いくつか重要な点に注意が必要です。
まずオーバーフィッティングを防止するため、データセットの特性や変数間の関係性を理解することが重要です。また、モデルのタイプや目的によって最適な手法が異なるため、状況に応じたアプローチを選択しましょう。
他の特徴エンジニアリングとの比較
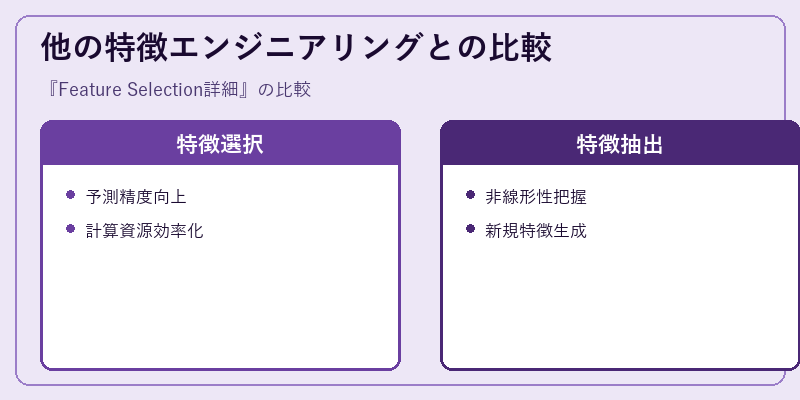
特徴エンジニアリングの一部として位置づけられる特徴選択は、他の手法と比較して何が異なるのでしょうか?
特徴選択は既存の変数から最適なものを選び出す一方で、特徴抽出は新たな特徴量を作り出し非線形性を捉える重要な役割を持っています。
まとめ
以上、特徴選択に関する概要と重要性を考察しました。機械学習モデルの性能向上と効率化に向けたステップの一つとして、今後も引き続き研究が続けられるでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







