
2014年にIan Goodfellowらによって考案されたGAN(敵対的生成ネットワーク)は、人工知能の分野において革新的なアプローチを提供した。この技術は二つのニューラルネットワーク、生成器と識別器を通じて画像や音声などのデータを生成し、その精度は驚異的なものがある。
この記事の目次
- GANの基本構造
- 訓練過程
- 応用例
- 比較: GANと他のモデル
- まとめ
GANの基本構造
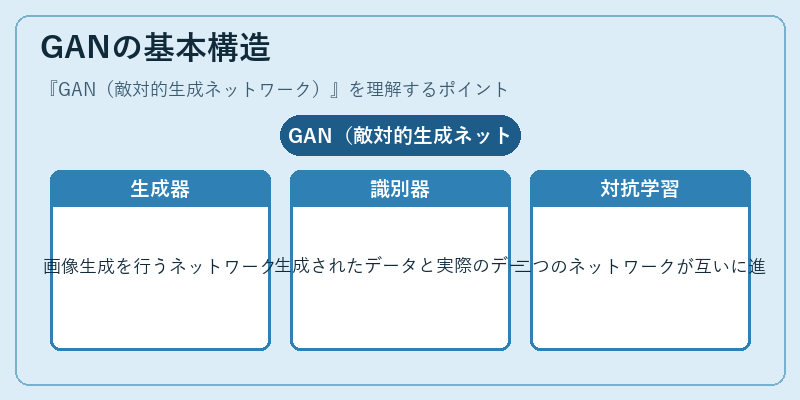
GANは生成モデルにおける革新的なアプローチとして、2つの重要なコンポーネントである生成器と識別器で構成される。これらの要素を用いて、システムは特定の種類のデータを模倣する画像や音声を作り出す能力を持つ。
例えば、GANは大量の顔写真から新しい個別の人物の肖像画を生成することが可能である。ここでは、生成器と識別器が互いに学習しながら進化し、最終的により高品質なデータ生成ができるようになる
訓練過程
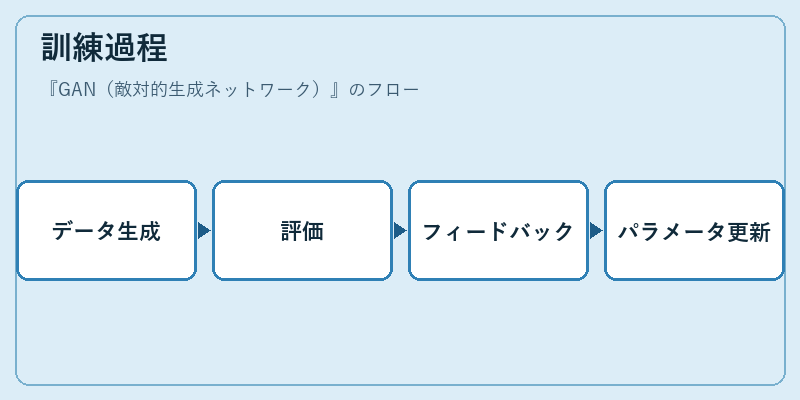
GANの訓練は対抗学習を通じて行われる。生成器は新しいデータを作り出し、識別器はその真偽を判断する。
このプロセスは繰り返される度に生成器と識別器がそれぞれの能力を向上させ、最終的には識別器が生成されたデータと実際のデータを区別できなくなるまで続く
応用例

GANは画像や音声データの生成に広く利用され、これら以外にも様々な忪用範囲を持つ。例えば、医療業界では、患者のCTスキャンから腫瘍のシミュレーションを作製することが可能となる。
一方で、映像コンテンツ産業においては、GANを利用してCGキャラクターを生成する技術が開発されている
比較: GANと他のモデル
他の画像生成モデルと比較して、GANはその独自性から大きな違いを生む。例えば、VAE(変分自己符号化器)は確率的な枠組みを利用してデータの分布を推定する一方で、GANは対抗学習によって生成力を高める。
このため、GANはよりリアルな画像や音声の生成が可能であるものの、同時に訓練時間も長くなるという特徴がある
まとめ
GANは人工知能における画期的な手法であり、その技術と応用範囲の広さから今後さらに発展が期待される。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







