
ガウシアンナイーブベイズは、機械学習における確率的推論の一つとして広く使用される。19世紀の統計学者ラプラスが提唱したベイズの定理を基盤とし、現代では大量のテキストデータの分類問題に効果的に利用されている。
この記事の目次
- ガウシアンナイーブベイズとは
- モデルの歴史と発展
- アルゴリズムの構造
- 比較対象:ロジスティック回帰
- まとめ
ガウシアンナイーブベイズとは
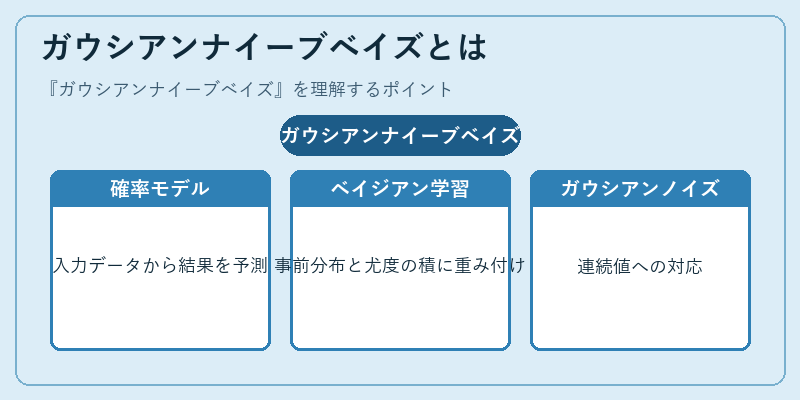
ガウシアンナイーブベイズは、確率モデルを用いてクラス分類を行う手法で、連続型データの予測に特に適している。その名前の由来となるガウス分布とベイジアン推論が組み合わさっている。
たとえば、テキスト分類において大量の文章からカテゴリを自動的に決定する際、ガウシアンナイーブベイズは文書内の単語の頻度や重要性を考慮しながら、各クラスに属する確率を計算する。
モデルの歴史と発展
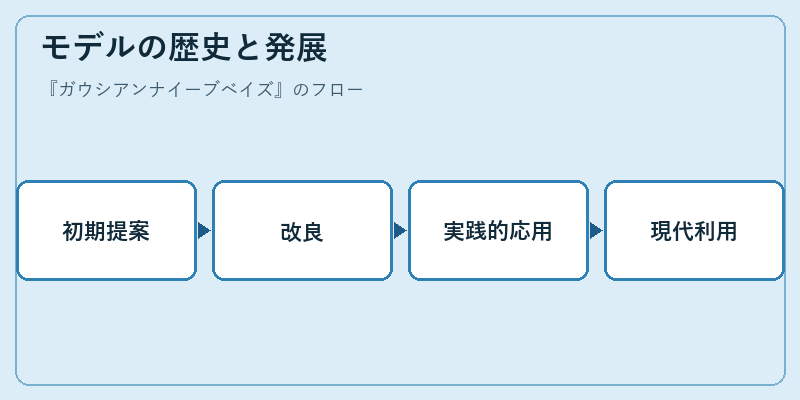
ガウシアンナイーブベイズは、19世紀にラプラスが発展させたベイジアン統計の理論に基づいている。その後20世紀に入り、コンピュータ科学者たちによって実装され始めた。
特に1970年代から80年代には、情報検索やデータベースの分類などに応用されるようになり、現在ではウェブ上の大量テキスト解析にも欠かせない存在となっている。
アルゴリズムの構造

ガウシアンナイーブベイズのアルゴリズムは、まずデータセットを準備し、それぞれの特徴量に対するガウス分布を学習する。
次に、各クラスの事前確率と尤度を計算し、最終的に予測値が算出される。これはシンプルながら効果的な分類アルゴリズムとして評価されている。
比較対象:ロジスティック回帰
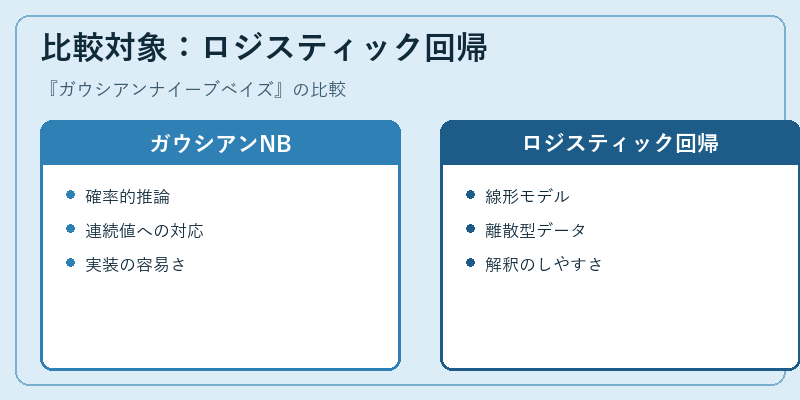
ガウシアンナイーブベイズは確率的推論を基盤とし、連続型データにも対応している一方で、ロジスティック回帰は線形モデルとしてシンプルである。
また、実装の難易度や解釈のしやすさも異なる。ガウシアンNBでは計算過程が少し複雑になる傾向があるが、その代わりに高度な統計的予測を可能にする利点もある。
まとめ
ガウシアンナイーブベイズは、テキストデータの分類において重要な位置を占めている手法である。確率モデルとベイジアン推論の組み合わせにより、様々な応用が可能となっている。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







