
ガウス混合モデル(GMM)は、多様なデータ分布を近似するための確率モデルとして、1960年代から研究され始めました。初期のベイジアン統計への貢献を経て、機械学習のクラスタリングや密度推定に広く使用されるようになりました。この記事ではGMMの基本構造と応用例について詳しく探ります。
この記事の目次
- GMMの数学的基礎
- クラスタリングへの応用
- 推定過程のアルゴリズム
- GMMとの比較
- まとめ
GMMの数学的基礎

GMMは、各クラスタが正規分布に従うと仮定した上で,それらを線形結合します。この混合モデルは多様なデータ形式に対応でき、それぞれの観測値がどのガウス分布から生成されたかを推定するための機械学習手法です。
クラスタリングにおいて,尤度関数はモデルの性能を評価し,各クラスタが観測値にどれだけ適切に対応しているかを表します。これにより,GMMのパラメータ調整と最適化を行うことができます。
クラスタリングへの応用

GMMは機械学習におけるクラスタリングアルゴリズムとして広く採用されています。この手法を活用することで,データの自然な集団分けが可能になり,新たな知見やパターン発見につながります。
例えば,画像認識では複雑な形状や色調の分布を捉えるためにGMMを使用します。これにより,画像内の主要構造を検出する精度が向上し,より詳細な情報抽出が可能となります。
推定過程のアルゴリズム
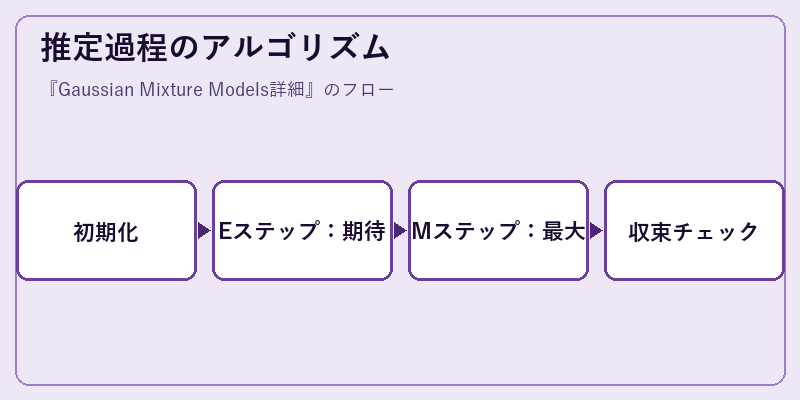
GMMの推定過程では,EMアルゴリズムが中心的役割を果たします。このアルゴリズムは,各観測データがどのクラスタに属するかを逐次的に推定し続けます。
EM法ではまずパラメータの初期値設定を行い(初期化)。その後,EステップとMステップを反復実行することでパラメータを更新していきます。このプロセスは収束条件が満たされるまで繰り返されます。
GMMとの比較
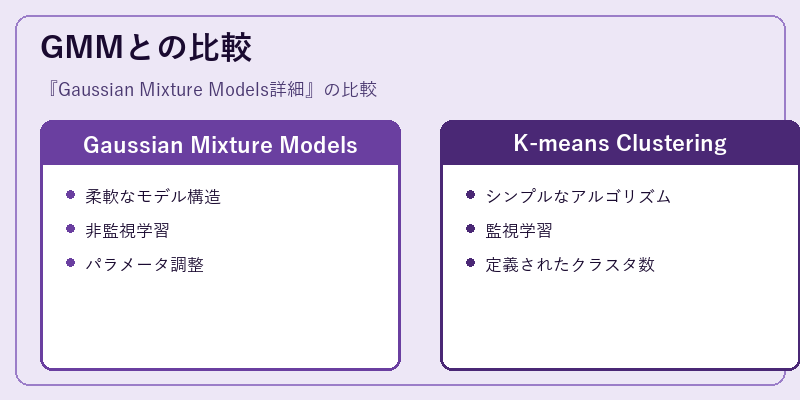
GMMは,データの複雑さに柔軟に対応するため,様々なモデル構造を有します。これに対して,K-meansでは明確なクラスタ数が必要となるため,適用範囲が制限されます。
さらに,GMMはEMアルゴリズムによってパラメータの最適化を行うことができますが,一方でK-meansは固定したクラスタ中心を基準として更新を行います。この差異によりそれぞれの手法には長所と短所があります。
まとめ
GMMは機械学習において重要な役割を果たすだけでなく,様々な問題解決に有用な柔軟性を持っています。その高度な理論的背景とともに,現実世界での活用例について深く理解することも大切です。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







