
GIN(Generalized Inverted Index)は、PostgreSQLが提供する特許取得済みのデータ構造で、大規模な非論理型データを効率的に検索可能にします。1990年代から開発が進められ、現在では特にテキストやJSONデータに対する高速クエリー処理において、重要な役割を果たしています。
この記事の目次
- GINインデックスの定義
- GINインデックスの歴史
- GINインデックスの内部仕組み
- GINインデックスとB-Treeインデックスの比較
- まとめ
GINインデックスの定義

GINインデックスは、PostgreSQLにおける特許取得済みのデータ構造で、非論理型データを効率的に保存し、高速なクエリ応答を可能にします。
この技術は、特に大規模なテキストやJSONデータベースにおいて、従来のB-Treeインデックスよりも優れた性能を発揮しています。
GINインデックスの歴史
GINインデックスは、1990年代初頭に、PostgreSQLの共同創設者であるMichael Stonebraker氏らによって開発されました。
その後、その技術はデータベース業界で広く認知され、多くの企業が商用利用を開始しています。現在も積極的な改良が続けられています。
GINインデックスの内部仕組み

GINインデックスは、内部で詳細な逆指標テーブルとデータ圧縮を使用してデータを保存します。これにより、大量の非論理型データに対するクエリーが高速化されます。
また、この構造は並列処理にも適しており、複数コアを持つ現代のハードウェア環境で効果的に機能します。
GINインデックスとB-Treeインデックスの比較
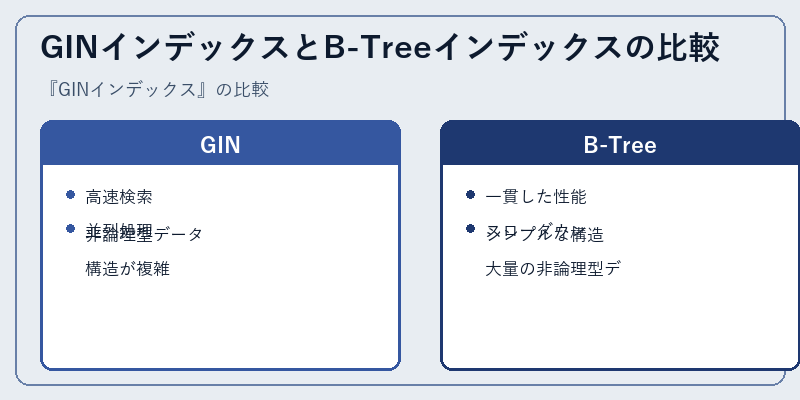
GINインデックスとB-Treeインデックスは、異なる目的を持つデータベース最適化技術です。前者は主にテキストやJSONなどの非論理型データを効率的に扱うために設計されていますが、後者は一般的なデータ検索において安定したパフォーマンスを提供します。
それぞれのインデックスでは、適用するデータタイプと処理要求により、最適な選択肢が変わることがあります。
まとめ
GINインデックスは、大規模な非論理型データベースにおいて高速かつ効率的なクエリ応答を可能にする重要な技術です。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







