
GiNZA(ギンザ)は、日本語自然言語処理を支えるツールキットであり、Mecab-Jaの派生版として生まれた。2019年からPythonライブラリとして展開され、BERTやRoBERTaなどのTransformerモデルと連携して高度なタスクに対応する。
この記事の目次
- GiNZAの起源
- GiNZAの仕組み
- GiNZAの機能
- GiNZAと他ツールの比較
- まとめ
GiNZAの起源
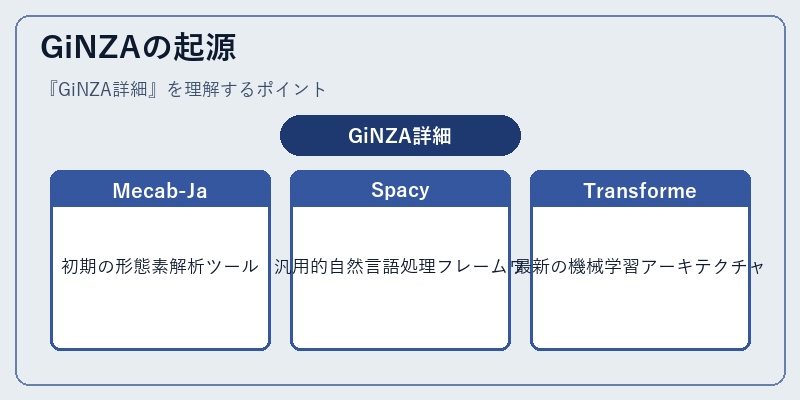
GiNZAは、日本語向け形態素解析ツールMecab-Jaから始まった。その後、Spacyという強力な自然言語処理フレームワークに統合され、現在ではTransformerモデルと連携している。
この進化の過程で、ユーザーが手軽に高精度な日本語NLPを実現できるようになった。例えば、GiNZAはSpacyの機能を利用して大量のテキストデータから素早く情報を抽出することができる。
GiNZAの仕組み
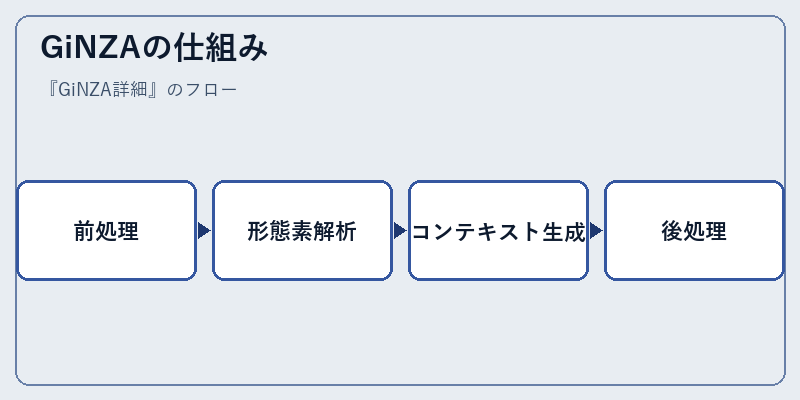
GiNZAは、入力された日本語テキストに対してまず前処理を実施する。これは、文字コード変換や特殊な文字の処理などを行う重要なステップである。
次に形態素解析を行い、単語と品詞情報を抽出する。この情報を使って、続いてコンテキスト生成が行われ、文脈理解力を持つTransformerモデルを活用し、最後には結果の後処理が実施される。
GiNZAの機能
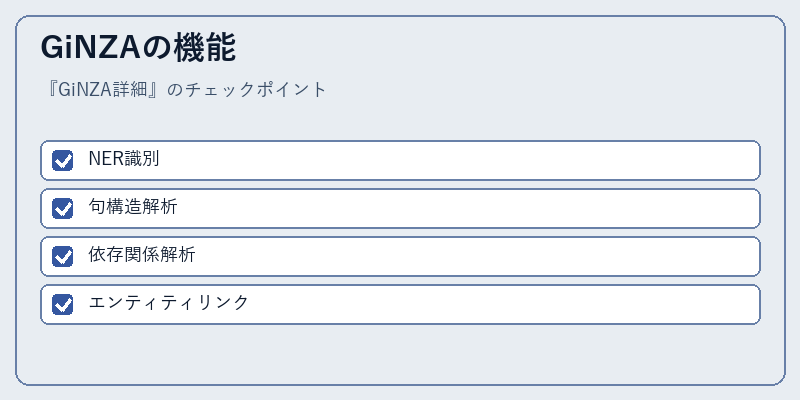
GiNZAは名詞認識、句構造解析、依存関係解析といった機能を提供する。これらの機能は、複雑な文脈の中でテキストデータの意味を正確に理解することを可能にする。
具体的には、エンティティリンクにより、文章中の特定の単語が何を指しているのかを判定できるようになり、より高度な情報検索や分類作業を行うことが容易になる。
GiNZAと他ツールの比較
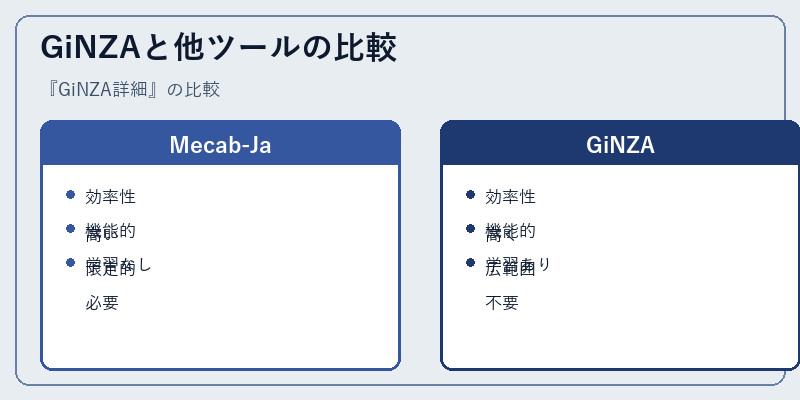
Mecab-Jaと比較すると、GiNZAは更なる高度な機能を提供する一方で、その性能を犠牲にすることなく効率性も保つ。また、ユーザーが自らモデルの学習を行う必要がないことも特徴的である。
しかし、特定の専門的な用途ではMecab-Jaのようなツールの方が適している場合もあるため、選択は状況により異なる
まとめ
GiNZAは日本語自然言語処理において有用なツールであり、その進化と共に新たな可能性が広がっている。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







