
grep -EはLinuxコマンドラインで、拡張正規表現を使用してファイル中の文字列を検索・抽出する機能を持つ。1970年代にUnix開発者のスティーブ・ボゾランが基礎を作り、現在では多数のオプションとサブセットを持ち、プログラミングやシステム管理で広く使用されている。
この記事の目次
- grep -E の概要
- grep -E の仕組み
- grep -E の歴史的背景
- 他の文字列検索ツールと比較
- まとめ
grep -E の概要
grep -Eは文字列検索のための重要なツールで、LinuxやUnix環境では標準的なコマンドとして利用される。複雑なパターンマッチングを可能にする拡張正規表現が特徴。
たとえば、ファイル内の特定の日付範囲を抽出する場合などに活用される。また、grep -Eは大規模なコードベースの分析やネットワークトラフィックモニタリングでも役立つ。
grep -E の仕組み
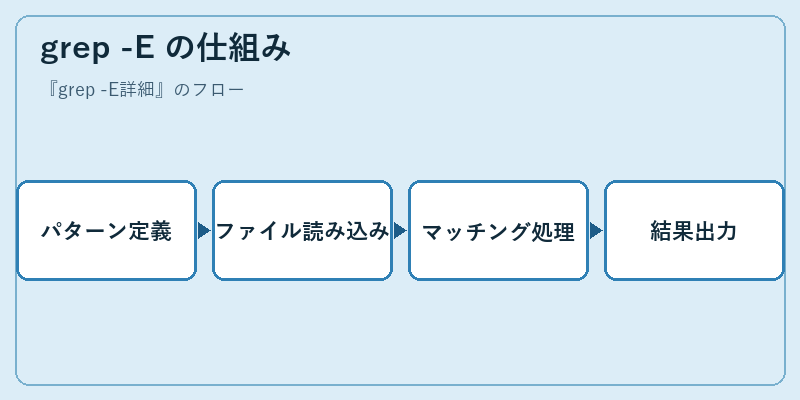
grep -Eの内部動作は、与えられた正規表現に基づき対象となる文字列を解析し、その中から一致する部分を検出し表示します。エスケープシークエンスや特殊なシンボルを使用して複雑なパターンを定義できます。
たとえば、特定のIPアドレス範囲を持つ全てのログラインを抽出するためには、grep -E “192.168.[0-3][0-9]” log.txt のように指定します。
grep -E の歴史的背景

grep -Eは、1970年代に発展したUnixシステムで開発され、スティーブ・ボゾラン氏によって作られました。当初は文字列検索ツールとしての役割から始まりましたが、時と共に多くの機能が追加されました。
特に、拡張正規表現の導入によりパターンマッチング能力が向上し、より高度な検索要求に対応可能になりました。今日でもgrepは頻繁に更新され、その必要性を満たすための進化を続けている。
他の文字列検索ツールと比較
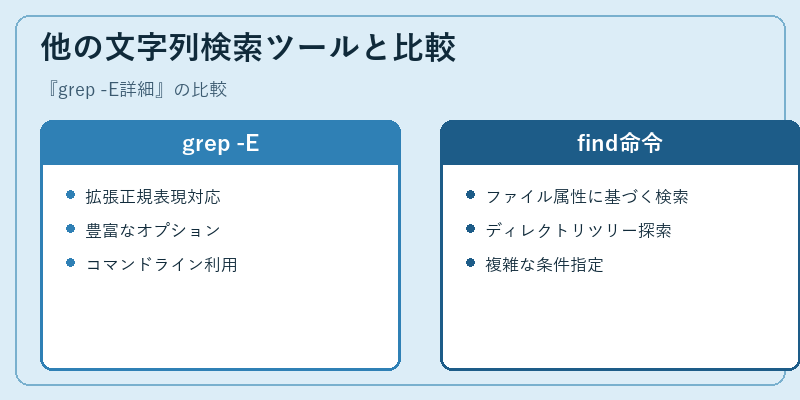
grep -Eは文字列のパターンマッチングに特化した一方、findコマンドはより広範な目的を果たす。findは特定のファイル属性に基づく検索やディレクトリツリー全体での探索を行う。
両者の比較では、grepは文字列が含まれるか否かの判定に適しているのに対し、findはサイズ・権限等の属性を用いたより広範囲な検索を可能とします。
まとめ
grep -Eは拡張正規表現を使用してファイル中の文字列を効率的に検索するための重要なツールであり、LinuxやUnixシステムの管理において不可欠な役割を果たしています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







