
grep -n コマンドは、1970年代に AT&T Bell Labs で開発された正規表現エンジン grep の一部として利用されるようになった。ファイル内で特定の文字列を検索し、見つかった行番号を表示する機能を提供します。
この記事の目次
- grep -n の基本的な仕組み
- grep -n の歴史的背景
- grep の内部処理フロー
- grep -n と find の比較
- まとめ
grep -n の基本的な仕組み
grep -n は、ファイル内の特定文字列を検索するためのコマンドとしてよく使用されます。このオプションにより、検索結果がどの行に存在するのかを正確に把握できます。
例えば、あるテキストファイルで ‘error’ と一致する行を探し出すとき、grep -n error filename.txt という形式で実行すると、該当する行の行番号と共にその内容が表示されます。
grep -n の歴史的背景

grep -n は、エディタ検索機能を補完するための正規表現エンジンとして開発されました。それ以前にもテキスト検索のツールは存在しましたが、grep の導入により効率的なテキスト解析が可能になりました。
その後 grep は多くの改良を重ね、そのうちの一つである -n オプションは行番号とともに結果を表示することでより詳細な情報提供が可能となりました。
grep の内部処理フロー
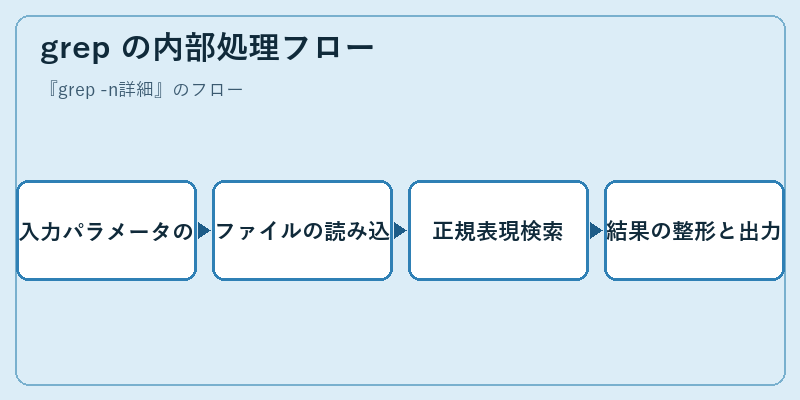
grep -n は、まずコマンドラインから受け取った文字列やオプションを解釈し、それらに応じて処理を行います。その後で指定されたファイルを開き、その内容を逐次的に読み進めます。
検索対象の行が見つかった場合、grep はその部分に対応する正規表現パターンと比較を行い、一致する場合には結果として該当する行番号とテキストを表示します。
grep -n と find の比較

grep -n と find の両者は、Linux シェルにおいてよく使われるコマンドであり、それぞれ異なる目的で利用されます。grep -n は特定の文字列を検索し、結果と共に行番号を表示します。
一方で find コマンドはファイルの属性やディレクトリ構造を対象に、より広範な条件に基づく探索を行います。これにより、OS の管理やファイルシステムの解析など多岐にわたるタスクが可能となります。
まとめ
grep -n の機能と歴史的背景、内部処理フロー、他の類似コマンドとの比較を通じて、このコマンドがLinux操作系における重要な役割を果たしていることが理解できるだろう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







