
Groq(グロック)は、元GoogleのTPU設計者であるJonathan Rossが2016年に創業した米国の半導体スタートアップです。同社が開発したLPU(Language Processing Unit)は、GPUとは異なるアーキテクチャでLLM推論を圧倒的な低遅延・高スループットで処理できる点が特徴で、Llama 3やMixtralを毎秒数百〜千トークン以上の速度で生成できます。GroqCloudというAPIサービスを通じて、開発者は専用ハードを保有せずにこの高速推論を利用でき、リアルタイム音声エージェントやエージェント連鎖など、応答速度が価値となる用途で急速に存在感を高めています。
この記事の目次
- LPUアーキテクチャの核心
- GroqCloudが提供するLLM推論API
- 活用ユースケースと組み合わせ
- 競争環境と今後の展望
- まとめ
LPUアーキテクチャの核心
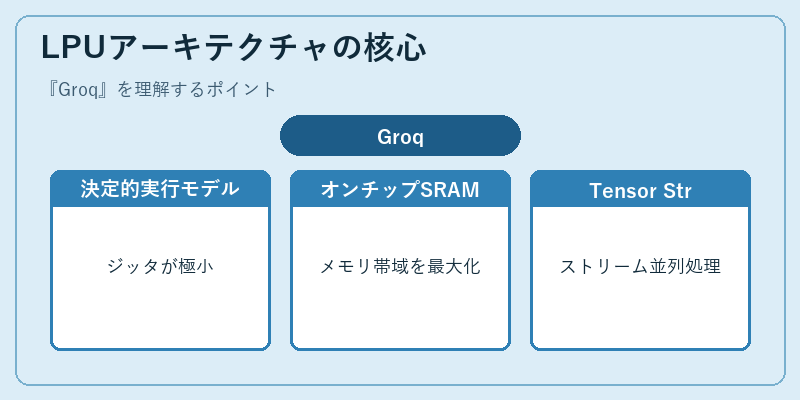
LPUの最大の特徴は、Tensor Streaming Processor(TSP)と呼ばれる決定的(deterministic)な実行モデルです。GPUのように動的スケジューラに頼らず、コンパイラがあらかじめ全ての命令配置とデータ移動をスケジュールするため、実行ジッタが極めて小さく、レイテンシが予測可能です。これにより、対話型LLMで重要な「最初のトークンが返るまでの時間(Time To First Token)」を大幅に短縮できます。
また、LPUは大容量のオンチップSRAMをコアに分散配置することで、HBMのような外部メモリのボトルネックを回避しています。LLM推論は本質的にメモリ帯域に律速されますが、SRAM中心の設計とコンパイラによる最適化で、GPUよりも高い実効スループットを実現します。さらに、複数チップを高帯域で接続するTensor Streaming Multiprocessor構成により、大規模モデルを数百チップに分散配置しても通信遅延を抑え込めます。
GroqCloudが提供するLLM推論API

GroqCloudは、OpenAI互換のREST APIでLLM推論を提供するクラウドサービスです。対応モデルにはLlama 3シリーズ、Mixtral、Gemmaなど主要OSS LLMが揃っており、ユーザーはAPIキーを取得するだけで、毎秒数百トークンの超高速応答を利用できます。OpenAI SDKの互換性が高く、base_urlを差し替えるだけで既存実装を移行できる点も魅力です。
従来、GPU上でのLlama 3 70B級モデルの推論は毎秒数十トークン程度に留まり、対話の遅延が体感的に気になるケースも多くありました。GroqのLPUはこれを一桁高速化することで、リアルタイム音声エージェントや、複数LLM呼び出しを直列で連鎖させるエージェントアーキテクチャ、長文の要約や検索エージェントなど、レイテンシ感度の高いユースケースで大きな差別化要素となります。
活用ユースケースと組み合わせ

Groqの強みが最も活きるのは「会話のテンポ」が価値となる領域です。音声エージェント、コンタクトセンター自動化、ライブ翻訳、対話型アシスタントなどでは、TTFTと毎秒生成トークン数が顧客体験を直接左右します。GroqとElevenLabsやDeepgramなどの音声基盤を組み合わせれば、人間との自然な会話に近い応答速度を実現できます。
また、エージェント設計においても恩恵が大きく、複数のツール呼び出しやチェイン推論を直列に走らせるとレイテンシが累積しますが、Groqを使えば各ステップを高速で完了できるため、エージェント全体の応答時間が現実的な範囲に収まります。RAGでの再ランキング、長文要約、ストリーミング読み上げなど、毎秒トークン数が体感に直結するシーンでも採用が進んでいます。
競争環境と今後の展望
AI推論専用チップ市場には、NVIDIAのGPU/Hopper/Blackwellに加え、Google TPU、AWS Inferentia/Trainium、Cerebras、SambaNova、Tenstorrentなど多くのプレイヤーが参入しています。Groqは「LLM推論の超低遅延」に特化することで明確なポジションを取り、GroqCloudというサービス型展開で開発者の手元に直接届けている点が独自です。NVIDIAエコシステムから一歩離れた選択肢として注目されています。
今後の課題は、対応モデルの拡充、ファインチューニングや独自モデル持ち込み、エンタープライズ向けプライベート展開、生成速度以外(コスト・モデル品質・長文コンテキスト)の総合競争力の維持です。LLM推論市場は需要の伸びと同時に価格競争も激化しており、Groqの専用ハードがどこまで規模拡大できるかが今後数年の見どころとなります。
まとめ
Groqは、LPUによる決定的な実行モデルとオンチップSRAM中心の設計で、LLM推論の超低遅延・高スループットを実現した独自の半導体企業です。GroqCloud経由でAPIから手軽に利用でき、音声対話やエージェント連鎖など応答速度が価値となるユースケースで強力な選択肢になります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント