
Apache Hadoopは2006年、米Yahoo!のDoug Cuttingらが Google の論文(GFS, MapReduce)を参考に開発した分散処理基盤です。「ノードが落ちる前提で大規模データを処理する」発想で、ビッグデータブームを牽引した立役者。HDFS(分散ファイルシステム)、YARN(リソース管理)、MapReduce(処理エンジン)の3層構造が中核で、2010年代のデータ基盤の代名詞となりました。
この記事の目次
- Hadoopの3層構造
- Hadoopエコシステム
- Hadoopの黄金期と衰退
- Hadoopから何を学ぶか
- まとめ
Hadoopの3層構造
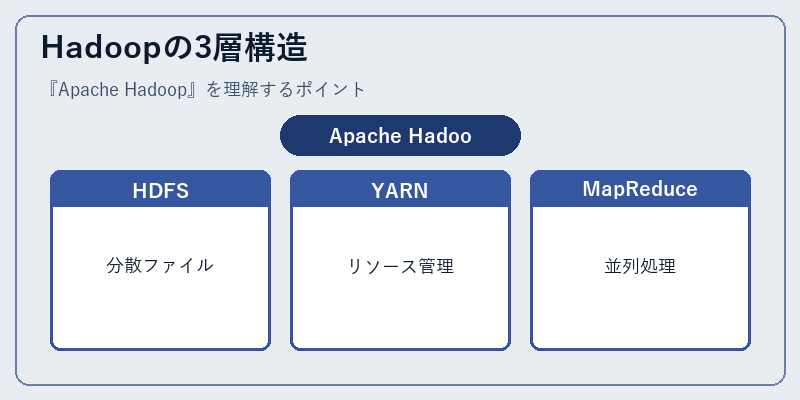
HDFS(Hadoop Distributed File System)はGoogle GFSにインスパイアされた分散ファイルシステムで、「ファイルを大きなブロックに分割し、複数ノードに複製して保存」する設計。ノード障害があってもデータが失われない冗長性が特徴です。
YARN(Yet Another Resource Negotiator)はクラスタ全体のリソース管理を担い、MapReduceは「Map(分散処理)→ Reduce(集約)」のシンプルなプログラミングモデルで巨大データを並列処理。「ノード数を増やせばリニアに性能が伸びる」スケーラビリティが当時の革新でした。
Hadoopエコシステム

Hadoop は本体だけでなく、周辺ツールの「Hadoopエコシステム」が広大です。Hive(SQL風クエリ)、HBase(NoSQL)、Pig(データフロー)、Sqoop(RDB連携)、Oozie(ワークフロー)など、用途別にApacheトップレベルプロジェクトが多数並びました。
「Hadoopを使えば何でもできる」と謳われ、Cloudera、Hortonworks、MapR等のディストリビューターが商用パッケージ化。2010年代前半は「ビッグデータ=Hadoop」という時代でした。
Hadoopの黄金期と衰退

Hadoopは2010年代前半が黄金期でしたが、後半に入って凋落します。理由はSparkがメモリ活用で MapReduceより速く・書きやすかったこと、クラウドのS3/BigQuery等が「自前でHadoopクラスタを管理する手間」を肩代わりしたこと、運用が複雑すぎたこと、など。
Cloudera が Hortonworks を吸収(2018)、IBMが Hadoop 関連事業を再編、と業界も激変。「Hadoopが死んだ」と言われがちですが、HDFS や Hiveは今もエンタープライズのオンプレデータレイクで使われており、完全に消えたわけではない、というのが実情です。
Hadoopから何を学ぶか

Hadoopは「自前クラスタで大規模分散処理する」モデルでしたが、現代は S3+Spark、Snowflake、Databricks Lakehouse、BigQuery のような「クラウドのマネージド分散処理」が主流。「分散処理のアイデア」自体は色褪せていないものの、運用形態が大きく変わりました。
Hadoopから学ぶべきは「ノード障害を前提に設計する」「ストレージとコンピュートを分離する」「MapReduce的な発想で並列化する」といった分散処理の基本パターン。これらは今も Spark、Flink、Snowflake などの設計の根底にあります。
まとめ
Apache Hadoopはビッグデータ時代を切り開き、分散処理の概念を普及させた歴史的に重要なフレームワークです。現在は主役の座をSparkやクラウドDWHに譲りつつも、設計思想とエコシステムは今も多くの場所で生きています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント