
Pythonの標準ライブラリ内のbuiltinsモジュールに属するhash()関数は、1980年代から現在まで広く使用されてきた。この記事ではhash()の基本的な機能と利用方法を解説し、その内部メカニズムやハッシュテーブルとの連携についても触れる。
この記事の目次
- hash関数の定義と目的
- hash関数とデータ型
- 内部メカニズム
- Pythonと他の言語の比較
- まとめ
hash関数の定義と目的
hash()は、特定のデータ型に基づく一意な数値を生成します。この数値は通常、メモリ効率や検索速度向上のために利用されます。
例えば、文字列”hello”に対するハッシュ値は、その文字列の各バイトコードの合計を元に計算されます。
hash関数とデータ型

hash()は全てのデータ型に対して効果を発揮するわけではありません。これは、その関数が生成した値の一意性と安定性を維持するためです。
例えば、タプルは不変なのでハッシュ可能ですが、リストは可変であるため非ハッシュ可能です。ただし、セットやフローズンセットでは一部の可変要素を許容します。
内部メカニズム
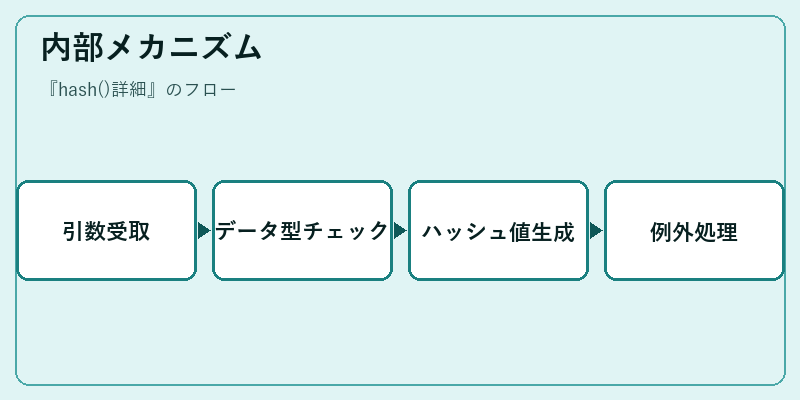
hash()はまず、ユーザーが指定したオブジェクトを受取ります。次にそのオブジェクトの種類に基づき、適切なハッシュ値計算アルゴリズムを選択します。
ここで生成されたハッシュ値はそのまま返されますが、データ型による例外処理も行います。可変性を持つオブジェクトではValueErrorがスローされます。
Pythonと他の言語の比較

Pythonのhash()は、言語内部で自動的に利用可能な一方で、他の言語ではユーザー定義が必要なケースもあります。
C#におけるGetHashCodeメソッドは、オブジェクト自体がハッシュ値生成と関連するパフォーマンスを直接制御できる柔軟性を持っています。
まとめ
hash()の詳細を理解することは、効率的なデータ検索やストレージ管理において重要です。ただし利用時には型の一貫性と適切な例外ハンドリングに注意が必要となります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







