
MLOps(Machine Learning Operations)は、機械学習モデルを本番システムへ継続的にデプロイ・運用・改善するためのプラクティスと、それを支える技術スタックの総称です。ソフトウェア開発で確立されたDevOpsの思想を機械学習に拡張する概念で、2015年にGoogleの研究者D. Sculleyらが発表した論文「Hidden Technical Debt in Machine Learning Systems」が、その問題意識を広く知らしめました。現在はGoogle・Microsoft・AWSの公式ホワイトペーパーや、MLflow・Kubeflow・DVCといった主要OSS群を軸に、業界横断の実践フレームワークとして整理が進んでいます。
この記事の目次
- MLOpsの三本柱
- MLOps概念の発展史
- 現場で実装される代表シナリオ
- DevOps・DataOpsとの関係
- まとめ
MLOpsの三本柱
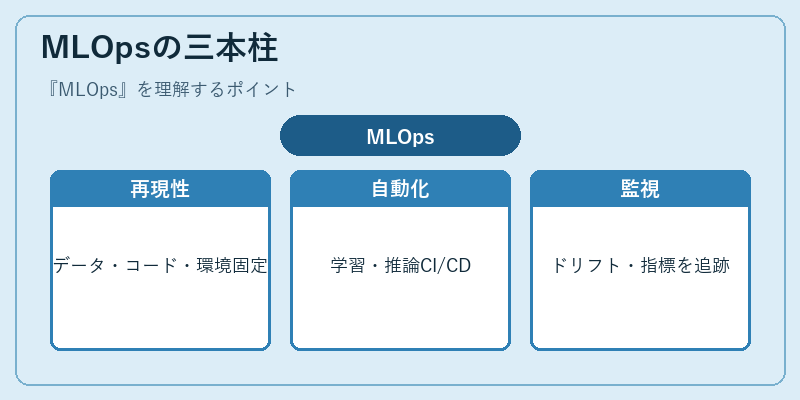
MLOpsの中心的な価値は、「学習データ・コード・実行環境のスナップショットを残し、いつでも同じモデルを再現できる状態を保つ」ことです。DVCやLakeFSによるデータバージョン管理、Gitによるコード管理、Dockerやcondaによる環境固定、MLflowやWeights & Biasesによる実験トラッキングを組み合わせ、「あの精度を出したモデルは何で作られたのか」を完全に追跡できる体制を作ります。再現できない実験はそもそも改善できないため、これがMLOpsの土台となります。
二本目の柱が自動化です。GitHub ActionsやArgo Workflows、Kubeflow Pipelines、Vertex AI PipelinesなどでCI/CDパイプラインを定義し、コードや設定の変更で自動的に学習・評価・デプロイが走るようにします。三本目が監視で、推論レイテンシ・スループットといったシステム指標に加え、データドリフト(入力分布の変化)やコンセプトドリフト(入出力関係の変化)、ビジネスKPIの変動を継続的に追い、必要に応じて再学習を起動します。この再現性・自動化・監視の3つが揃ってはじめて、機械学習が単発のPoCではなく持続可能な事業の一部になります。
MLOps概念の発展史

MLOpsの問題意識を決定づけたのが、2015年にGoogleのD. Sculleyらが発表した論文「Hidden Technical Debt in Machine Learning Systems」です。ML本体のコードはシステム全体のごく一部に過ぎず、設定管理・データ収集・特徴量抽出・モニタリング・サービングなど「周辺コード」が膨大な技術的負債を生むという主張が、業界に強いインパクトを残しました。翌年からはGoogleの内部ツールTFX、Uberのミシェランジェロ、Airbnbのbighead、Netflixのmetaflowなど、各社のML基盤事例が次々と公開されます。
OSS側では2018年にDatabricksがMLflowを発表し、実験トラッキング・モデルレジストリ・デプロイ用パッケージングを統合した最初の本命ツールキットとして広まりました。2019年にはKubernetes上のML基盤Kubeflowが本格普及し、パイプラインと分散学習を一気通貫で運用する選択肢が整います。2020年代に入るとGoogle Cloud Vertex AI、AWS SageMaker MLOps、Azure Machine LearningといったクラウドのフルマネージドサービスがMLOpsを標準機能として提供し始め、概念は技術というより「ML組織の運営原則」として広く定着しました。
現場で実装される代表シナリオ

MLOpsの代表的な実装パターンは、学習パイプラインの完全自動化です。GitリポジトリにコミットがあるたびにCIがデータバージョンとコードを取得して再学習を行い、評価指標が閾値を超えれば自動でモデルレジストリに登録、さらにステージング環境へデプロイする、というフローを構築します。MLflow Model RegistryやVertex AI Model Registryが代表的なレジストリ実装で、モデルにはステージ(Staging/Production/Archived)と署名情報が記録されます。
本番デプロイではABテストやシャドーデプロイ(既存モデルにトラフィックを流しつつ新モデルも同じ入力で推論させて結果を比較する手法)が広く採られます。稼働開始後はEvidently、WhyLabs、Arize、Fiddlerなどのドリフト監視ツールで入力分布と予測分布を継続観測し、ビジネスKPIや指標の悪化が検知されたら自動で再学習ジョブを起動する、という閉ループを構築します。金融・医療・広告など、モデルの性能劣化が直接損益に響く業界では、この監視+再学習サイクルがMLOpsの肝として特に重視されています。
DevOps・DataOpsとの関係
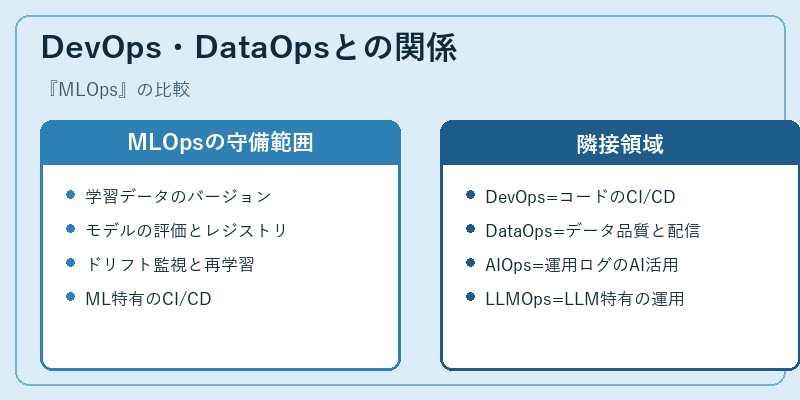
DevOpsは「アプリケーションコードの開発と運用を一体化する」プラクティスで、CI/CD、IaC、モニタリング、ポストモーテムといった共通要素を持ちます。MLOpsはその思想を機械学習に拡張したもので、ML特有の課題(データバージョン、特徴量管理、評価指標、モデルドリフト、再学習)を追加で扱います。DataOpsはデータパイプラインの品質・配信・SLAに焦点を当てる隣接領域で、MLOpsはDataOpsが提供する「整ったデータ」の上に乗って機能します。
近年はAIOps(運用ログをAIで分析・自動化する領域)やLLMOps(LLM特有のプロンプト管理・評価・ハルシネーション対策・ベクトル検索運用などをカバーする新しい潮流)が独立した概念として議論されるようになっています。LLMOpsは厳密にはMLOpsの一部ですが、評価が定量化しにくい、プロンプトとモデル選択の組み合わせが大きい、ベクトルDBやRAGパイプラインを伴う、といった独自要素が多く、専用のツール(LangSmith、Helicone、Promptlayerなど)も育っています。これら全体を「ソフトウェア工学のCI/CDをデータ・モデル・プロンプトまで拡張する取り組み」と捉えるのが、現代的なMLOpsの全景です。
まとめ
MLOpsは2015年のGoogle論文「Hidden Technical Debt in ML Systems」に端を発し、MLflow・Kubeflow・DVCといったOSS群とクラウドサービスの整備を経て、機械学習を持続的事業に変えるための標準プラクティスとして確立されました。再現性・自動化・監視を三本柱に、DevOps/DataOps/LLMOpsと連携しながら、現代のAIシステムを支える運用工学として進化を続けています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント