
RayはUCバークレーRISELab発の汎用分散計算フレームワークで、2017年にRobert Nishihara氏とPhilipp Moritz氏らが論文「Ray: A Distributed Framework for Emerging AI Applications」と共に公開しました。Pythonの関数やクラスに@ray.remoteを付けるだけで、ノード横断の並列・分散実行へと拡張でき、強化学習や大規模ハイパーパラメータ探索、データ前処理、LLM学習・サービングまでをひとつのスタックで覆えるのが特徴です。Apache 2.0ライセンスで提供され、商用支援を行うAnyscale社が中心となって開発しています。
この記事の目次
- Rayを構成する三つの層
- RISELab発祥からAnyscale設立まで
- Rayが活きる代表ワークロード
- Spark・Daskとの違い
- まとめ
Rayを構成する三つの層
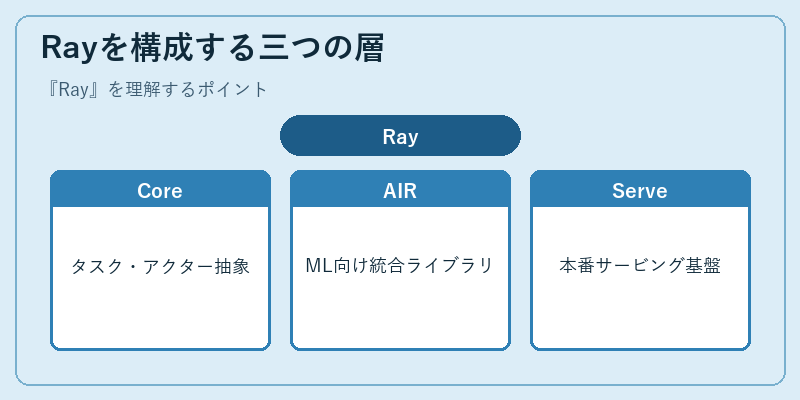
Ray Coreは、Python関数を分散タスクに、Pythonクラスを状態を持つアクターに変換する低レベルAPIです。@ray.remoteデコレータを付けてfunc.remote(args)と呼ぶと、Rayクラスタ上の任意のワーカーで非同期に実行され、戻り値はObjectRefという未来オブジェクトとして扱われます。アクターは長寿命の状態を保つので、強化学習エージェントやキャッシュ付きの推論サーバーなど、状態と並列処理が両立しなければならない問題にきれいに収まります。
その上に、Ray AIR(AI Runtime)と総称される機械学習向けライブラリ群が乗ります。Ray Tuneはハイパーパラメータ探索、Ray Trainは分散学習、Ray Dataはストリーミングデータ処理、RLlibは強化学習、Ray Serveはモデルサービング、と役割ごとに整理されており、相互運用が前提です。学習でもサービングでも、同じRayクラスタを使い回せるため、運用基盤の重複を避けられる点が大規模プロジェクトに歓迎されています。
RISELab発祥からAnyscale設立まで

Rayは、UCバークレーでSparkを生んだAMPLabの後継研究室RISELabで、Robert Nishihara氏とPhilipp Moritz氏らが2016年から研究を始めた分散計算プロジェクトを起源とします。2017年にOSDIで「Ray: A Distributed Framework for Emerging AI Applications」が発表され、強化学習やオンライン学習のような新しいAIワークロード向けに設計された分散ランタイムとして注目を集めました。2018年にApache 2.0ライセンスでGitHubに公開され、コミュニティ主導で成長していきます。
2019年、Nishihara氏とMoritz氏、指導教官のIon Stoica教授らはAnyscale社をサンフランシスコで創業し、Rayの商用支援とマネージドクラウドを提供し始めました。2022年のRay 2.0では、Tune/Train/Data/Serveなどを統合管理する「Ray AIR」のコンセプトが整理され、ML/LLM時代の本命分散基盤としての地位を固めます。現在はOpenAIやUber、Spotify、Cohere、Anthropicなど多数の企業で運用事例が報告されており、特にLLM学習のクラスタ管理や、強化学習研究での標準基盤として広く採用されています。
Rayが活きる代表ワークロード

Rayは強化学習との相性が抜群で、RLlibを使えば数千の並列環境を回しながらPPOやIMPALA、APEX-DQNといったアルゴリズムを分散学習できます。OpenAIがChatGPTの学習でRayを利用したことを公表しており、強化学習ファインチューニング(RLHF)におけるロールアウト並列化基盤として広く使われています。Ray Tuneを使えば、scikit-learn・PyTorch・HuggingFace Transformersのハイパーパラメータ探索を、PBTやASHAなど先端アルゴリズムで効率化できます。
LLM領域ではRay Serveが推論サービングの基盤としてよく選ばれ、複数モデルやLoRAアダプタを動的にロード・スケールアウトする運用に向いています。Ray Dataはペタバイト級のデータを並列前処理する用途で力を発揮し、画像・テキスト・動画を分散シャードに分けてバッチ推論する典型パターンを支えます。ストリーム処理や時系列の特徴量計算、シミュレーション結果の集約など、「Pythonで書きたいが計算量はスケールアウトしたい」場面が、Rayの主戦場です。
Spark・Daskとの違い
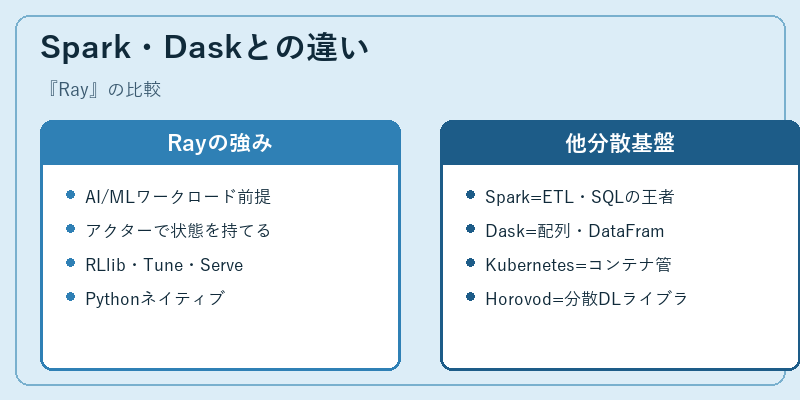
Apache SparkはETL・SQL・バッチ分析の王者で、巨大表データの結合・集計や、構造化された機械学習パイプライン(MLlib)で大きな存在感を持ちます。Daskはnumpy/pandasの分散版という性格が強く、配列・DataFrame演算を透過的にスケールアウトすることに長けています。これに対しRayは、AI/MLワークロード、特に「状態を持つ計算」「強化学習」「分散ハイパラ探索」を中心に設計されており、関数だけでなくアクターを第一級で扱える点が決定的に異なります。
実務では、データレイクのETLやSQLバッチ集計はSpark、配列演算が支配的な数値計算はDask、強化学習やLLM学習・サービングはRay、と棲み分けるのが現実的です。Kubernetesはこれら全部の下に居るコンテナオーケストレーション基盤で、Ray・Spark・Daskはいずれもk8s上で動かすパターンが一般化しています。Horovodはディープラーニング学習に特化したライブラリでRay Trainからも統合呼び出しが可能で、用途に応じた組み合わせがしやすいエコシステムが整っています。
まとめ
RayはUCバークレーRISELab発、Anyscale社が育てる汎用分散計算フレームワークで、強化学習からLLM学習・サービングまでをPythonネイティブに支える基盤として定着しました。Tune・Train・Data・Serve・RLlibを統合したAIRレイヤーが特徴で、Spark・Daskとの棲み分けを取りながらAI/ML時代の分散実行を背負う中核技術になっています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント