
Apache Sparkは2009年、カリフォルニア大学バークレー校AMPLab(後のRISELab)で開発が始まった分散データ処理エンジンです。2014年にApacheトップレベルプロジェクト化、商用版はDatabricks社が主導。Hadoop MapReduceの後継として「メモリを活用して高速に分散処理する」モデルで一気に普及し、大規模データのETL・分析・機械学習・ストリーミング処理を1つの基盤で実行できる存在になりました。
この記事の目次
- SparkがHadoopより速い理由
- Sparkを構成するコンポーネント
- Sparkの実行環境
- Sparkと類似技術の使い分け
- まとめ
SparkがHadoopより速い理由
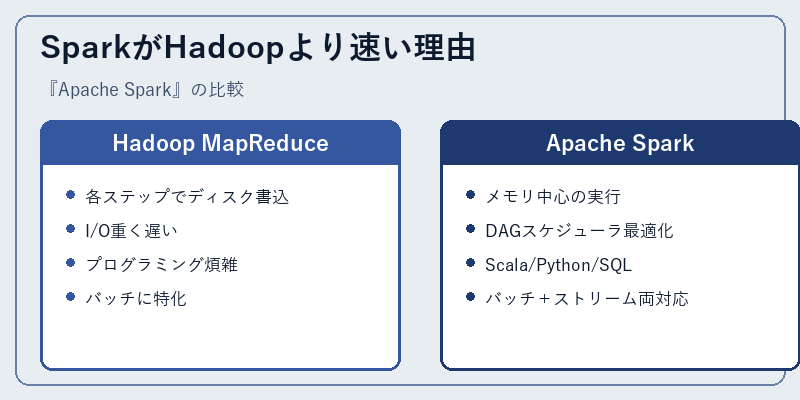
SparkがHadoop MapReduceより最大100倍速いと言われる理由は、中間結果をディスクに書かずメモリ上で連結処理するから。RDD(Resilient Distributed Dataset)→DataFrame→Datasetという抽象化により、DAG(有向非巡回グラフ)で処理を最適化し、不要なI/Oを削減します。
プログラミング面でもMapReduceより簡潔で、Scala(純正)、Python(PySpark)、SQL(Spark SQL)、Java、Rで書けるため、データエンジニア・データサイエンティストの双方に普及しました。
Sparkを構成するコンポーネント
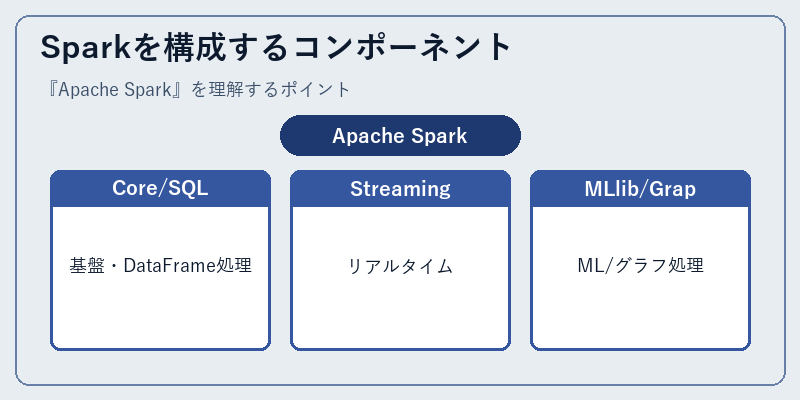
Sparkは複数のサブシステムで構成されています。Spark Coreが基盤、Spark SQLがDataFrameやSQLでの操作、Spark Streamingが擬似的なリアルタイム処理、MLlibが機械学習、GraphXがグラフ処理。これらを一つのクラスタで動かせるのが「統合基盤」の魅力です。
近年は Structured Streamingという新しいストリーミングAPIが主流で、「DataFrameの操作と同じコードで、バッチでもストリーミングでも動く」設計が広く使われています。
Sparkの実行環境
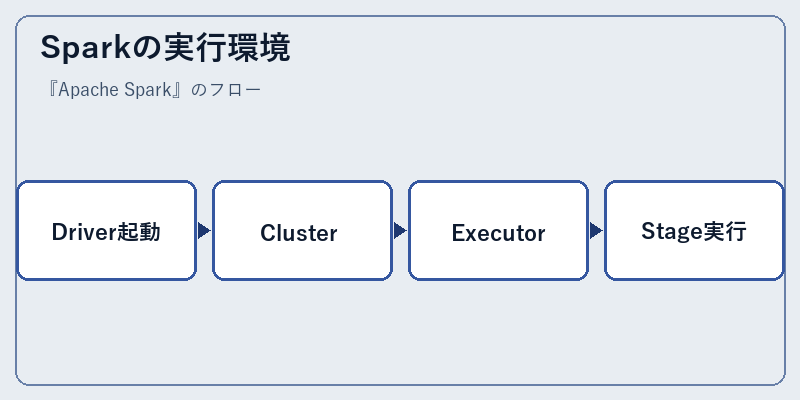
Sparkはマスター(Driver)と多数のワーカー(Executor)からなるクラスタで動きます。クラスタ管理は YARN、Kubernetes、Mesos、または独自のスタンドアロンモードから選べます。ジョブを送信するとDriverがStageに分解し、Executor群に分配します。
クラウドではAmazon EMR、Azure HDInsight / Synapse、Google Dataproc、Databricks Lakehouseが代表的な実行先。「クラスタ管理を任せて利用に集中できる」マネージドサービス利用が現代の主流です。
Sparkと類似技術の使い分け

Sparkは「大規模分散データ処理の万能選手」と言える存在ですが、用途特化で勝る競合もあります。Apache Flinkは真のストリーミング処理に強く、リアルタイム性が最優先ならFlinkが選ばれます。対話的なBI分析にはPresto/Trinoのほうがオーバーヘッドが少ない場面も。
ELT/データウェアハウス系では、Snowflake/BigQuery + dbtという構成が増えており、「Sparkで巨大バッチを処理」「dbtで日次変換を管理」のように役割分担する現場が多くなっています。
まとめ
Apache Sparkはビッグデータ時代の基幹エンジンとして広く採用され、現代も最重要級のデータ処理基盤です。PySpark経由でデータ分析やML処理に関わるなら、Sparkの仕組みと運用知識は必須スキルになります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント