
DVC(Data Version Control)はサンフランシスコのスタートアップIterative.ai社が中心となって開発するOSSのデータ・モデルバージョン管理ツールです。創業者のDmitry Petrov氏(元Microsoft、PhDの研究者)が2017年に公開し、「Gitに馴染んだ開発者のワークフローのまま、テラバイト級データセットや巨大モデルファイルもバージョン管理できる」ことを目指しています。S3・GCS・Azure Blob・SSH・HDFSなど多様なリモートストレージをサポートし、データセットのハッシュとパイプライン定義をGitリポジトリに残すことで再現性を担保します。
この記事の目次
- DVCを支える三つの仕組み
- Iterative.aiの設立と進化
- DVCがフィットする場面
- Git LFS・MLflowとの違い
- まとめ
DVCを支える三つの仕組み
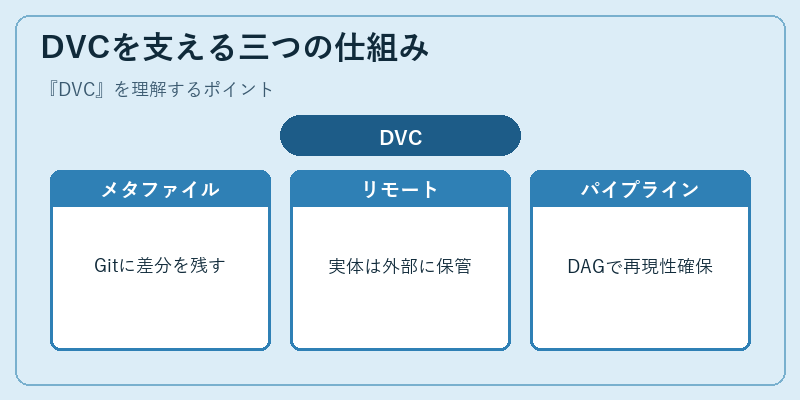
DVCの基本動作は、dvc add data/train.csvのようにファイルやディレクトリを登録すると、その実体は.dvc/cacheにコンテンツアドレッシングで保存し、Git管理対象には小さな.dvcメタファイル(ハッシュとパス)だけが追加される、というものです。結果として、巨大ファイルをGitリポジトリに直接コミットせずに、「あの時点のデータはこれ」というスナップショットを軽量メタファイル経由で追跡できるようになります。Git LFSのデータセット版という位置付けで理解すると掴みやすいでしょう。
二つ目の柱がリモートストレージ管理です。dvc remote add storage s3://my-bucket/dvcのようにS3やGCS、Azure Blob、SSH先などをリモートとして登録し、dvc push/dvc pullでGitと同じ感覚でデータを同期できます。三つ目がパイプライン機能で、dvc.yamlにステージ(前処理→特徴量→学習→評価)と入出力を宣言しておけば、DAGとして実行順序を管理し、入力データやコードが変更されたステージだけを再実行できます。結果、データ・コード・モデル・指標が一貫してバージョン管理され、再現性のある実験管理が成立します。
Iterative.aiの設立と進化

DVCはDmitry Petrov氏が2017年5月にGitHubで初版を公開したのが始まりです。Petrov氏は元MicrosoftのデータサイエンティストでPhDも持ち、社内で機械学習プロジェクトを進めるなかで「データセットがGitに乗らないせいで再現性が崩れる」という課題を強く感じてDVCを構想したと語っています。翌2018年にはIvan Shcheklein氏らと共にIterative.ai社をサンフランシスコで設立し、OSSとしての開発と商用支援を両輪で進める体制を整えました。
その後Iterative.aiは、GitHub ActionsやGitLab CIから機械学習パイプラインを呼び出せる「CML(Continuous Machine Learning)」、実験指標の比較・可視化を行う「DVC Studio」、ハイパーパラメータ探索のための「DVCExp」など、関連OSSを次々と公開しました。ヨーロッパ・北米のスタートアップから大企業のML部門まで、ユーザー層は広がり続けています。Apache 2.0ライセンスのOSSとして開発が続き、コミュニティとIterative.aiの社員によって毎月のように機能追加が行われており、DataOps・MLOpsの標準ツールキットの一つとして定着しました。
DVCがフィットする場面

DVCが最も力を発揮するのは、データセットやモデルが頻繁に更新される研究・実務プロジェクトです。例えば医療画像分類で、新しい施設からデータが追加されるたびにバージョンが上がる場面では、dvc addで取り込み、Gitブランチごとに異なるデータセット状態を共存させられます。ある実験が「v3データ+notebook A+モデルB」で出した結果は、対応するGitコミットへチェックアウトしてdvc pullするだけで完全に再現可能です。
実験管理の文脈ではdvc.yamlにステージを書いておくと、各ステージのメトリクス(精度・損失など)がmetrics.jsonとしてGitに残り、dvc exp showコマンドでブランチ横断のリーダーボードとして表示できます。GitHub Actions+CMLと組み合わせれば、PRごとに学習を自動実行し、結果のグラフ・指標をPRコメントに貼り付けるGitOps風MLパイプラインも構築できます。Hugging FaceやAirflow、MLflowなどと組み合わせる事例も多く、「データの変更点を誰でも追える状態」を維持するために重宝されています。
Git LFS・MLflowとの違い

Git LFSはバイナリ大容量ファイルをGitで扱うためのプラグインで、データ自体のサイズ問題は解消しますが、パイプライン管理や実験比較の機能は持ちません。DVCはここに、コンテンツアドレッシングのキャッシュ、任意リモートストレージ、DAGパイプライン、メトリクス比較を加えた上位ツールという位置付けです。「データセットをGitに乗せる以上のこと」が必要になった瞬間にDVCが優位になります。
MLflowはDatabricks発の実験管理ツールで、実験のラン単位でパラメータ・メトリクス・成果物をトラッキングし、UIで比較する用途に強みがあります。Weights & BiasesはSaaSとしてリッチなダッシュボードを提供し、共同実験管理に特に向きます。Pachydermはk8sネイティブなデータパイプライン基盤で、よりインフラ寄りの選択肢です。実務では「データ自体のバージョン=DVC、実験のラン管理=MLflow/W&B、ETLパイプライン基盤=Airflow/Pachyderm」と組み合わせて、層ごとに最適なツールを選ぶのが現実的なMLOps構成になっています。
まとめ
DVCはIterative.ai社のDmitry Petrov氏が2017年に始めた、Gitワークフローに馴染むデータ・モデルバージョン管理ツールです。メタファイル+リモートストレージ+DAGパイプラインの組み合わせで再現性を担保し、CMLやStudioと連携してGitOps風MLOpsを実現する基盤として、研究室から商用ML部門まで広く採用されています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント