
Apache Druidは、大量のデータを高速に処理し可視化するリアルタイムアナリティクス用のオープンソースデータストアです。2013年にMetamarkets社によって開発され、その後Apacheソフトウェア財団の下でコミュニティによる開発が続けられています。ここではDruidの仕組みや特徴について詳しく解説します。
この記事の目次
- Apache Druidの主要な機能
- Druidのアーキテクチャ概要
- Druidの主な利点
- Druidと他のデータストアの比較
- まとめ
Apache Druidの主要な機能
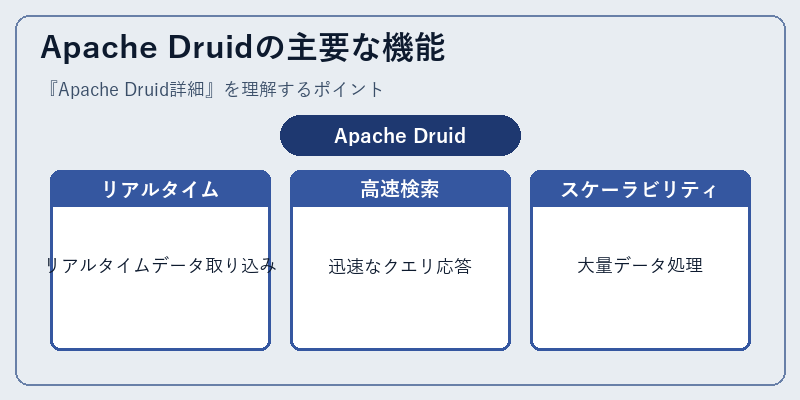
Druidは、多数のデータソースから流入する大量のデータを効率的に処理します。その強力な機能群には、リアルタイムでのデータ取り込みや高速検索などが含まれます。
具体的には、複数ノードで分散処理を行うことで大規模データセットにも柔軟に対応できます。また、あらゆる形態のデータソースからデータを連続的に取得して分析に活用します。
Druidのアーキテクチャ概要
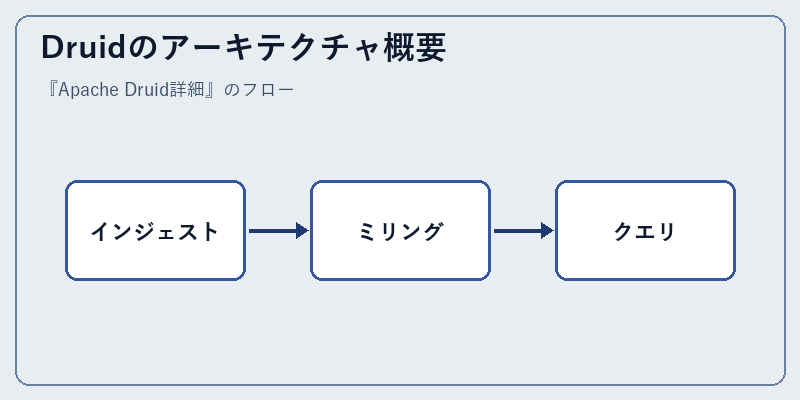
Druidの構成は複雑ながら効率的なもので、データを効果的に処理します。まずインジェストフェーズではデータを受け入れ、その後データセットに変換します。
ミリング過程においては、データが適切な形式に整理され、クエリに対して最適化されます。これによりユーザからの要求に即座に対応可能となります。
Druidの主な利点

Druidは高いパフォーマンスと拡張性を兼ね備えたプラットフォームとして知られています。各セクションで説明したような特長がこの評価に貢献しています。
特に、大容量のデータセットをリアルタイムで分析し、ビジネスインテリジェンスやユーザビヘイビア分析などの多様な用途に活用することができます。
Druidと他のデータストアの比較
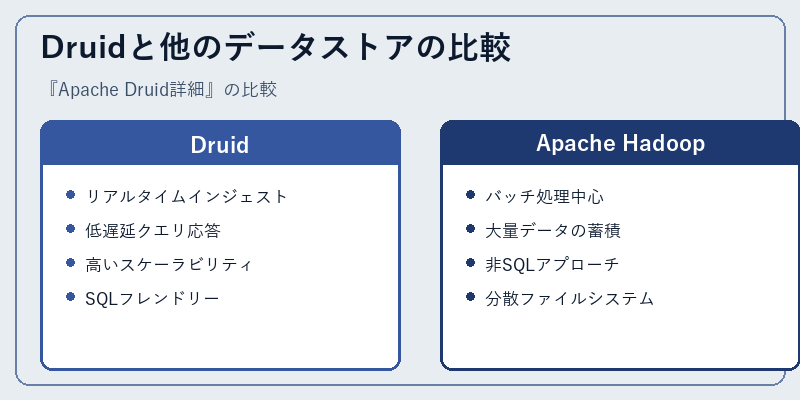
Druidは他の多くのオープンソースデータ管理ツールと異なり、リアルタイム分析を重視しています。一方で、Hadoopなどの既存技術との比較も重要な視点です。
例えば、Druidのリアルタイムインジェスト機能と低遅延クエリ応答は、Hadoopとは異なるアプローチを採用していますが、両者とも大規模データセットの管理において重要な役割を果たします。
まとめ
Apache Druidはリアルタイム分析における革新的なソリューションであり、データ駆動型ビジネスにとって不可欠な存在と言えます。その技術的特性と柔軟性から、様々な業界で幅広い活用が期待されています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント