
2014年に開発が開始された Apache Flink は、リアルタイム分析と高い並列処理能力を特徴とするデータ処理プラットフォームです。その卓越した性能と柔軟性は、デジタルトランスフォーメーションに取り組む企業にとって不可欠のツールとなっています。
この記事の目次
- Apache Flinkとは
- Flinkの歴史的背景
- Flinkの処理メカニズム
- 他のデータフレームワークとの比較
- まとめ
Apache Flinkとは

Apache Flinkは、一連のタスクやジョブを高効率で実行するためのフレームワークです。このフレームワークは複数の機能を持つことから、その用途は非常に広範です。
例えば、Flinkはストリーミングデータとバッチ処理の両方をサポートします。これにより大量のデータに対するリアルタイム分析や効率的な大量データ処理が可能となります。
Flinkの歴史的背景

Apache Flinkは、フロリダ工科大学とドイツのデータサイエンススタートアップ Stratio によって開発されました。その初期版では、パフォーマンスと柔軟性を追求するためのアーキテクチャが設計されました。
その後、2014年にApacheプロジェクトとして採択され、同年にFlinkの最初のバージョンがリリースされました。2015年にはApacheソフトウェア財団に正式加盟し、現在では多くの組織で使用されています。
Flinkの処理メカニズム

Apache Flinkは、複数のデータソースからの流入データを効率的に処理するためのフレームワークです。これにより、リアルタイム分析や分散システムにおける大量データの処理が可能となります。
例えば、ユーザー行動ログの分析ではFlinkを使ってストリーミング処理を行います。その結果は即時に出力され、さらには各種データベースやファイルシステムに保存されます。
他のデータフレームワークとの比較
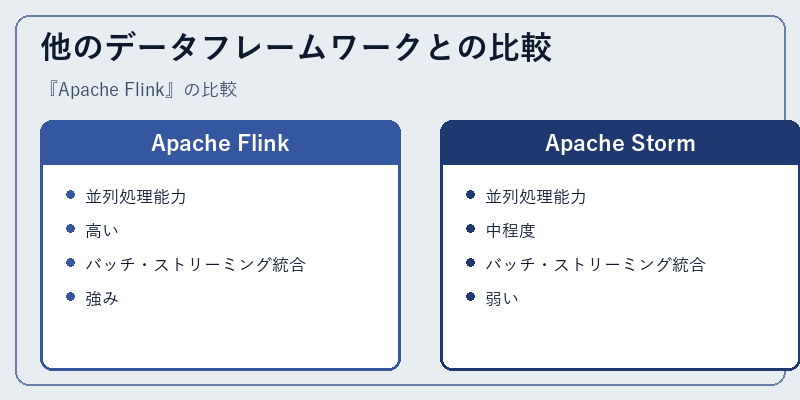
他のデータフレームワークと比較した場合、Flinkはその卓越した性能により多くの優位性を有します。特にApache StormやHadoop MapReduceといった他のフレームワークに比べて並列処理能力が高いことが特徴です。
また、ストリーミングとバッチの統合的なサポートも大きな強みと言えます。これにより、データ分析において柔軟性が増し、より効率的な結果を導き出すことができます。
まとめ
Apache Flinkはその性能と柔軟性から多くの企業で活用されていますが、その技術的な深淵さを理解するには一定の学習が必要となります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント