
MLX(エムエルエックス)は、2023年12月にAppleが発表したApple Silicon向けの機械学習フレームワークです。M1/M2/M3/M4チップに搭載されたユニファイドメモリ、Neural Engine、Metal Performance Shadersを最大限活用し、Macやアプリ内部でLLMや拡散モデルを効率的に学習・推論できるよう設計されています。NumPyに似たPython APIと、PyTorchに近い高レベルAPIを併せ持ち、研究者やアプリ開発者がローカル環境で生成AIを動かす際の有力な選択肢となっています。
この記事の目次
- MLXの設計思想と独自性
- MLX vs PyTorch MPSの違い
- 活用例とコミュニティ
- 今後の展望と注意点
- まとめ
MLXの設計思想と独自性

MLXの最大の特徴は、Apple Siliconが採用するユニファイドメモリ・アーキテクチャ(UMA)をフルに活用している点です。CPUとGPUが同じ物理メモリを共有するため、デバイス間のデータコピーが原則不要となり、PyTorchなど他フレームワークで起きがちなto(device)のオーバーヘッドを大幅に削減できます。これは特に大規模モデルを限られたメモリ容量で動かす際に大きな意味を持ちます。
また、MLXは演算を即時実行せず計算グラフとして遅延評価する「Lazy Evaluation」を採用しています。これにより、不要な中間結果のメモリ確保を避け、グラフ全体を見渡した最適化やカーネル融合が可能になります。Python APIはNumPy互換に寄せられているため、研究者は既存知識を活かしながらApple Silicon向けに最適化された計算を記述できます。
MLX vs PyTorch MPSの違い
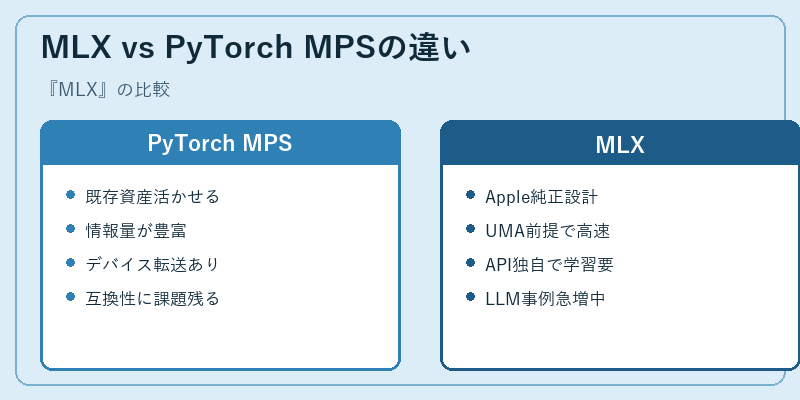
Apple SiliconでMLを動かす方法としては、PyTorchのMPS(Metal Performance Shaders)バックエンドも存在し、既存PyTorchコードを多少の修正で動かせます。利点は資産流用とコミュニティの厚みですが、もともとCUDA前提で書かれた抽象を移植している都合上、性能や安定性で課題が残るケースもあります。
一方MLXは、Apple Siliconを前提として一からAPIと内部実装を設計しているため、ユニファイドメモリやNeural Engineの活用に隙が少なく、特にLLM/拡散モデル分野で高い性能を引き出しています。代わりに、PyTorchと完全互換ではないため、コードや知識の再学習が必要になります。実務では、既存資産はMPSで、新規にローカル生成AIを設計するならMLXで、と使い分ける構成も現実的です。
活用例とコミュニティ

MLXの公開後、コミュニティはmlx-examples、mlx-lm、mlx-vlmといったリポジトリを次々と立ち上げ、Llama、Mistral、Phi、Gemma、Qwen、Stable Diffusionなど主要モデルの実装と量子化版(INT4/INT8)を整備しました。M3 MaxやM4などのMacBook Pro上で、毎秒数十トークン以上の速度で7B〜70BクラスのLLMを動かせる事例も多く、ローカル生成AIの実用性を引き上げています。
また、Appleが提供するCore MLやMetalとも連携し、MLXで学習したモデルをiPhoneやiPadなどオンデバイスアプリへ落とし込むワークフローも整いつつあります。教育・研究分野では、Apple Silicon搭載Macが一台あれば、データセンタGPUなしでLLM/拡散モデルの研究が進められる点で人気が高まっており、ハッカソンや個人開発との相性が抜群です。
今後の展望と注意点
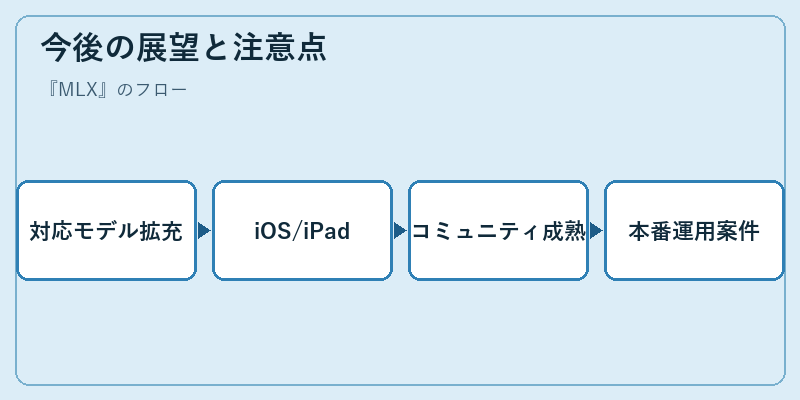
MLXはまだ若いフレームワークですが、Apple Silicon上のローカルAI開発における事実上の中心になりつつあります。今後の進化軸としては、対応モデルの拡充、量子化技術の高度化、iOS/iPadOS/visionOSとのより緊密な統合、エコシステム上のチュートリアル・教材整備などが挙げられます。Apple自身がオンデバイスAI戦略を強化する中で、MLXの位置付けは年々重要度を増していくと見られます。
一方、本番運用にあたっては、CUDAエコシステムほど成熟していない点に注意が必要です。分散学習や大規模クラスタへの展開、エンタープライズ向けサポート、長期API安定性などはまだ発展途上であり、データセンタ向けの大規模AI開発はNVIDIA GPU中心が現実的です。MLXは、Apple Siliconという特定ハード上のローカル・エッジ生成AIの最適解として位置付けるのが妥当でしょう。
まとめ
MLXは、Apple Siliconのユニファイドメモリと多種ユニットを最大限活かす設計で、Macとモバイル端末上のローカル生成AIを実用域へ押し上げたフレームワークです。CUDAとは異なる土俵で、オンデバイスAIや個人開発、教育用途における強力な選択肢として今後も存在感を増していくでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント