
Triton Inference Server(トライトン推論サーバ)は、NVIDIAが提供するオープンソースの推論サービングプラットフォームです。TensorRT、PyTorch、TensorFlow、ONNX Runtime、Pythonバックエンドなど多種のモデルを同一サーバ上でホストでき、HTTP/gRPC APIや動的バッチング、マルチGPU負荷分散、モデルアンサンブル、メトリクス連携など、本番推論基盤に必要な機能を一通り提供します。NeMo、TensorRT-LLM、MLflowなどと組み合わせることで、エンタープライズのLLM・コンピュータビジョン・音声系AI基盤を効率よく構築できる、デファクトの選択肢の一つです。
この記事の目次
- Tritonの基本アーキテクチャ
- 代表的な機能群と活用シーン
- TensorRT-LLM/vLLMとの組み合わせ
- 導入時のベストプラクティス
- まとめ
Tritonの基本アーキテクチャ
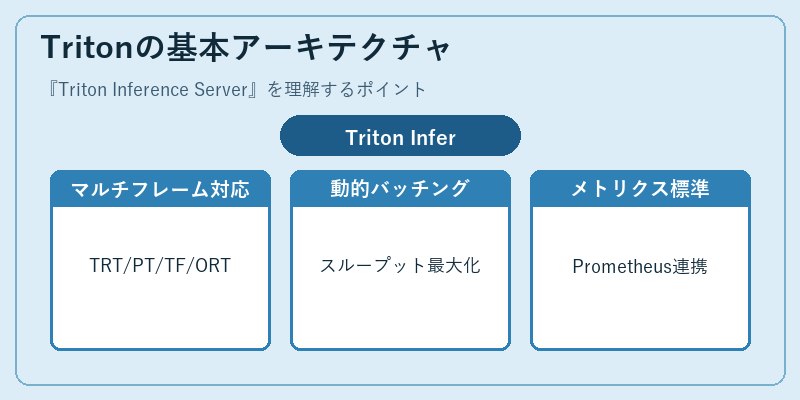
Triton Inference Serverは、モデルリポジトリと呼ばれるディレクトリ構成で複数のモデルを管理します。各モデルはバックエンド種別(TensorRT、PyTorch LibTorch、TensorFlow SavedModel、ONNX Runtime、OpenVINO、Pythonカスタム、FIL、Ensemble、BLSなど)に応じたフォーマットで配置され、設定ファイル(config.pbtxt)で入出力スキーマやインスタンス数、動的バッチング設定などを定義します。
クライアントはHTTP/RESTまたはgRPCを経由して推論リクエストを送り、サーバ内部ではキューイング、バッチ統合、GPU割り当て、レスポンス整形などが自動的に行われます。Prometheus互換のメトリクスを標準で公開しており、リクエスト数、レイテンシ、GPU稼働率、メモリ使用量などをGrafana等で可視化できるため、SREやMLOpsチームにとって扱いやすいシステムになっています。
代表的な機能群と活用シーン

Tritonの代表的な機能の一つが「動的バッチング(Dynamic Batching)」です。短時間に到着した複数リクエストを自動でバッチ化することで、GPUの計算効率を高め、スループットを大きく改善します。バッチサイズや遅延許容値を設定できるため、レイテンシ要件とスループット要件のバランスを柔軟に調整できます。
また、複数モデルを連結して一つのエンドポイントとして公開する「Model Ensemble」や、Pythonバックエンドで前後処理を書ける柔軟性も強力です。さらにLLM向けには、In-flight Batching、ストリーミングレスポンス、TensorRT-LLMやvLLMバックエンドへの対応が進み、推論サーバとしてのカバー範囲が大きく広がっています。コンピュータビジョン、音声、レコメンド、LLMなど多様な領域で、本番推論プラットフォームの中核として採用されています。
TensorRT-LLM/vLLMとの組み合わせ

LLM時代において、TritonはNVIDIA TensorRT-LLMのフロントエンドとして特に重要な役割を担っています。TensorRT-LLMで最適化したLlama 3、Mixtral、Qwenなどを、Tritonのトークンストリーミングやマルチインスタンス機能と組み合わせることで、複数ユーザーの同時利用に耐える高スループット・低遅延のLLM APIを構築できます。
もう一方の選択肢として、OSSのvLLM(UC Berkeley発)をTritonのバックエンドとして使う構成も普及しています。vLLMはPagedAttentionなど独自の最適化を持ち、複数モデル間でのKVキャッシュ共有や連続バッチングに強みがあります。Tritonはこれら最先端のLLM推論エンジンを統合するハブとして機能し、APIゲートウェイ、認証、メトリクスを担当しつつ、エンジン側はバックエンドのアップグレードに応じて柔軟に進化できる点が魅力です。
導入時のベストプラクティス

Triton導入時には、まずモデルリポジトリの構成と命名規則を整理することが重要です。モデルのバージョニング(v1/v2など)、バックエンド種別、GPU割り当て、動的バッチング設定をconfig.pbtxtで一貫したルールに沿って記述しておくと、後の運用が圧倒的に楽になります。CI/CDでモデルを自動デプロイする際にも、リポジトリ単位の差分管理が活きます。
次に、本番投入前の負荷試験が欠かせません。Perf Analyzerと呼ばれる公式ツールでスループット・レイテンシ曲線を取得し、動的バッチ設定やインスタンス数を調整します。Prometheus/Grafanaでのメトリクス可視化、Triton付属のModel Analyzerによる構成最適化、A/Bテスト用のモデルバージョン切り替えなどを組み合わせれば、本番品質の推論基盤として継続的にチューニング可能になります。
まとめ
Triton Inference Serverは、複数フレームワーク・複数モデルを統合的にホストし、本番運用に必要な機能を網羅したNVIDIA製OSS推論サーバです。TensorRT-LLMやvLLMと組み合わせることでLLM時代のエンタープライズ要件にも対応でき、AI推論基盤の中核として安心して採用できる選択肢となります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント