
SentencePieceは、Googleが2018年に公開した言語非依存のサブワード分割ツールで、工藤拓氏らによる論文「SentencePiece: A simple and language independent subword tokenizer and detokenizer」と同時にOSSとして発表されました。事前に形態素解析を行わず、生のテキストをそのままバイト列・Unicode列として受け取り、BPE(Byte-Pair Encoding)またはUnigram言語モデルで語彙を学習する点が他のトークナイザと大きく異なります。T5・mBART・ALBERT・LLaMAなど多くの多言語モデルで採用され、日本語や中国語のような分かち書きが不要な言語でも安定して使えるのが強みです。
この記事の目次
- BPEとUnigramの2つの学習方式
- 工藤拓氏らによる2018年公開
- 学習と推論での主な使い道
- 他トークナイザとの違い
- まとめ
BPEとUnigramの2つの学習方式
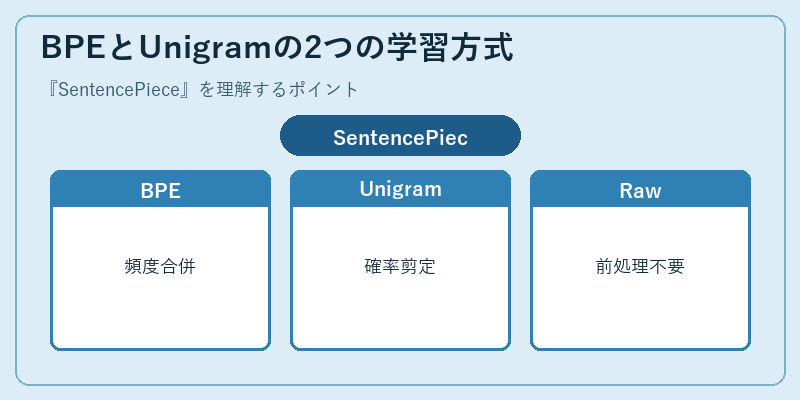
SentencePieceは2種類の学習アルゴリズムを切り替えられます。1つはBPE(Byte-Pair Encoding)で、最初は1文字ずつをトークンとし、コーパス中で隣接して現れる頻度が高いペアを順番に併合していく方式です。もうひとつはUnigram言語モデルで、巨大な候補語彙からスタートし、各候補のスコアをEMアルゴリズムで推定してコーパスの尤度が下がりにくい順に語彙を剪定していきます。
どちらの方式でも、SentencePieceは入力テキストを単語に分けずバイト列・Unicode列として扱い、空白を「▁」(U+2581)という特殊記号に置き換えてからサブワード分割を行います。復元時には▁を空白に戻すだけでよく、トークン化と元テキストへの戻し(detokenize)が完全に可逆になる点も大きな特徴です。これにより日本語のような単語境界が曖昧な言語でも、英語と同じパイプラインを共有できます。
工藤拓氏らによる2018年公開

SentencePieceは2018年8月、Googleブレインの工藤拓氏とリチャード・リチャードソン氏の論文がEMNLPワークショップで発表され、同時にGitHubのgoogle/sentencepieceリポジトリでオープンソース公開されました。工藤氏は形態素解析器MeCabの作者として知られ、自然言語処理コミュニティで「言語に依存しないトークナイザ」を強く意識した設計を提示しました。
公開直後からGoogleの研究グループがALBERT・T5・mT5・mBARTなどに採用し、多言語モデルで「単語の概念があやふやな言語」を扱う際の事実上の標準ツールになりました。2020年代に入るとMeta社のLLaMA・LLaMA 2・LLaMA 3も語彙構築にSentencePieceを採用しており、大規模言語モデルの基盤として広く使われています。日本語・中国語・タイ語のような分かち書きを必要としない言語にとっては、コーパスを与えるだけで語彙が学習できる利便性が大きな評価点となっています。
学習と推論での主な使い道

SentencePieceは大規模言語モデル・機械翻訳モデルの学習時に、コーパスから語彙を構築する用途で広く使われています。コマンドラインまたはPython APIにテキストファイルと「語彙サイズ32000」のようなパラメータを渡すと、BPEまたはUnigramの語彙ファイル(.model・.vocab)が出力され、推論時はそれを読み込むだけで同じトークン化を再現できます。数十言語をまたぐmT5やNLLBのような翻訳モデルでは、SentencePieceの言語非依存性がそのまま強みになります。
サブワード化により未知語(OOV)がほぼ消える点も実用上重要です。新語や固有名詞は複数のサブワードに分解され、生成タスクでも構造的に安定します。ドメイン特化、例えば医療・法律・プログラミングコードといった特殊領域向けの言語モデルを学習する場合、そのドメインのコーパスでSentencePieceを再学習して語彙を組み直すことが定番手順となっており、トークン効率が大きく改善することが知られています。
他トークナイザとの違い
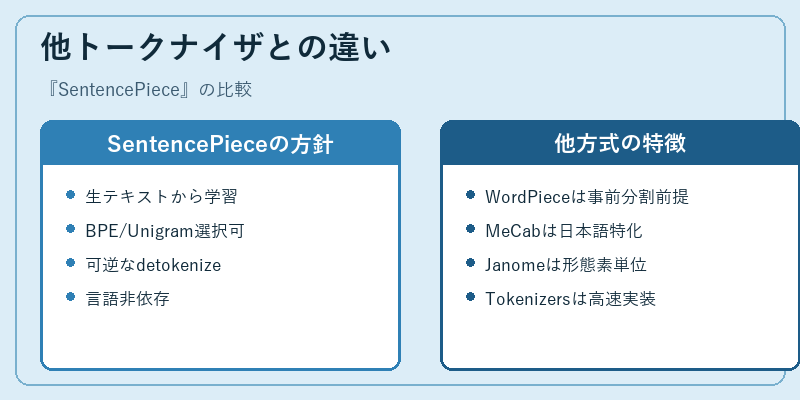
BERTで使われるWordPieceは、事前に空白で単語に分割してからサブワード化する前提があり、空白の概念が曖昧な言語で扱いづらいという課題がありました。MeCabやJanomeのような形態素解析器は日本語に特化しており、高精度な品詞付与ができる反面、辞書整備のコストや言語依存性が高くなります。SentencePieceはこの2つの中間に位置し、空白も含めて生のテキストから自動的に語彙を作るため、用意するのはコーパスだけで済みます。
一方で、Hugging FaceのTokenizersライブラリはRust実装で同等のアルゴリズムをより高速に動かせるため、推論時のトークン化はTokenizersに切り替える運用も増えました。実際の現場では「語彙の学習はSentencePieceで行い、推論時はTokenizersに移植する」あるいは「両方のAPIを併用する」といった構成が一般的です。SentencePieceはLLM基盤の語彙ファイルの「源流」として、いまも多くのモデル設計の前提に存在しています。
まとめ
SentencePieceは2018年にGoogleの工藤拓氏らが発表した言語非依存のサブワード分割エンジンで、BPEとUnigram言語モデルを切り替えて使えます。生テキストから語彙を学習し、可逆なdetokenizeが可能な設計により、T5・mBART・LLaMAなど多くのモデルで採用されました。形態素解析を持たない言語でも扱いやすいため、多言語LLMの語彙基盤として現代の生成AIに広く組み込まれています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント