
Transformersは、ニューヨーク発のHugging Face社が2018年に公開したPython製ライブラリで、BERT・GPT・T5・LLaMAなどTransformerアーキテクチャの事前学習モデルを統一APIで扱える点が最大の特徴です。創業者のクレマン・ドラング氏、ジュリアン・ショーモン氏、トマ・ウルフ氏のチームが、もともとチャットボット向けに作っていた内部ライブラリを「pytorch-pretrained-BERT」として公開し、その後transformersにリネームしてPyTorch・TensorFlow・JAX対応へ拡張しました。Hugging Face Hubと組み合わせ、研究と実装をつなぐ業界標準として2026年現在も中心的な地位を保っています。
この記事の目次
- AutoClassとパイプラインの設計
- BERT公開から業界標準までの経緯
- 現場での主な使い方
- 他フレームワーク・APIとの比較
- まとめ
AutoClassとパイプラインの設計
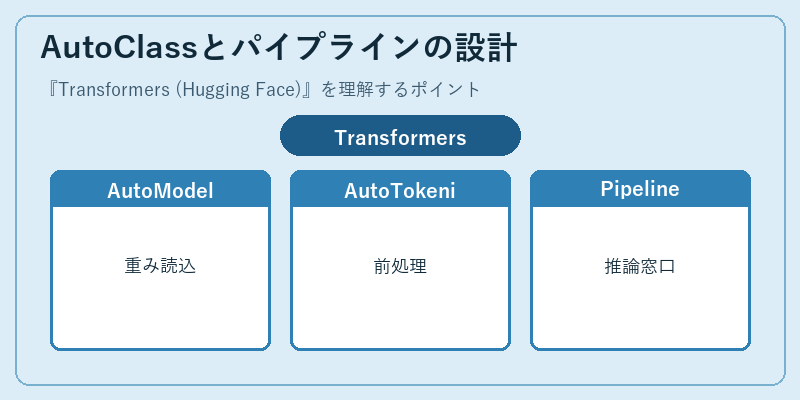
Transformersの設計思想は、モデルごとに異なるアーキテクチャの差をAutoModel・AutoTokenizer・AutoConfigという「Auto系クラス」で吸収し、利用者が文字列のモデル名を渡すだけで対応するクラスを自動選択できる点にあります。from_pretrained(‘bert-base-uncased’)のように書けば、Hugging Face Hubから重みとトークナイザがダウンロードされ、PyTorchやTensorFlowのモデルとして読み込まれる、という流れが共通化されています。
より高レベルにはpipeline関数があり、’sentiment-analysis’や’translation_en_to_fr’といったタスク名を渡すだけで、前処理・推論・後処理を一気に通す「箱」として動作します。この層構造のおかげで、研究者は内部のforward関数まで触れる柔軟性を確保しつつ、アプリ開発者は数行のコードで最新モデルを試せます。PEFT・Acceleratorといった他ライブラリと組み合わせる際も、Transformersのモデルクラスが共通の中心になります。
BERT公開から業界標準までの経緯

Transformersの原型は2018年10月、GoogleがBERTの論文と公式実装(TensorFlow)を発表した直後にさかのぼります。Hugging Face社が「PyTorchで動くBERTのラッパーが欲しい」というユーザー要望に応える形で、11月にpytorch-pretrained-BERTを公開したのが始まりです。研究者がたった数行でBERTを試せる体験は瞬く間に広まりました。
2019年9月、トマ・ウルフ氏らが論文「Transformers: State-of-the-Art Natural Language Processing」を発表する頃には、GPT-2・XLNet・RoBERTa・DistilBERTなど多数のモデルを統合し、transformersへとリネームされました。Hugging Face Hubの登場で世界中の研究者が自前モデルを共有するエコシステムが形成され、2020年代に入るとT5やBLOOM、LLaMA、Mistralなど代表的なオープン重みがほぼ全てtransformers対応で公開される状況になり、事実上の業界標準ライブラリとして定着しました。
現場での主な使い方

Transformersは「最新の事前学習モデルをすぐ動かす」用途で広く使われています。カスタマーサポートのテキスト分類モデルをBERTベースで作り、Trainer APIで自社データに微調整するパターンは典型例です。翻訳や要約はMarianMT・mBART・T5などをpipelineで包んで社内APIに公開する流れが一般化しており、PoC段階でもすぐに動かせます。
RAG(検索拡張生成)の文脈では、sentence-transformersや独自のエンベディングモデルをTransformers経由で読み込み、ベクトルDBに格納する処理に組み込まれます。LoRAやQLoRAといった軽量微調整も、PEFT・Acceleratorと組み合わせれば数十GBクラスのLLMをコンシューマGPUで学習でき、オンプレや自社クラウドにLLMをデプロイしたい場面では、ONNX・vLLM・TGI(Text Generation Inference)と連携した推論基盤の中核として置かれます。
他フレームワーク・APIとの比較
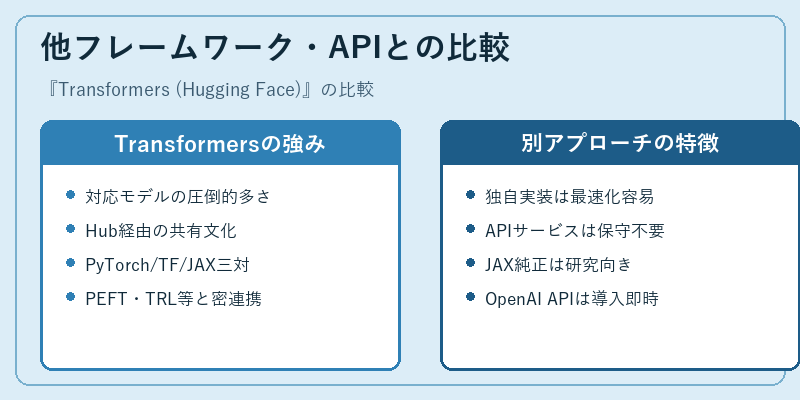
BERT以前は、研究室ごとに別実装のモデルを動かす状況が普通でした。Transformersは「同じAPIで多数のモデルを試せる」標準化を持ち込んだ点で大きな転換点となり、いまでは数万モデルがHubに登録されています。PyTorch・TensorFlow・JAXに横断対応していること、PEFTやTRL、Acceleratorといった周辺ライブラリが密に統合されている点も他にはない強みです。
一方で、推論の最適化に振り切るならvLLMやTensorRT-LLMといった専用エンジンの方が高速ですし、そもそもAPIサービス(OpenAI・Anthropic・Google)を使えばモデル運用の手間自体を省けます。Transformersは「自前で重みを管理しながら、最新研究の知見を即座に取り込む」現場で本領を発揮するライブラリで、クラウドAPIとは競合というより、自社運用が必要な領域の中心ピースとして補完的な位置にあります。
まとめ
Transformersは2018年にHugging Faceがpytorch-pretrained-BERTとして公開し、トマ・ウルフ氏らの論文を経て業界標準ライブラリへ成長しました。AutoClassとpipelineで多様な事前学習モデルを統一APIで扱え、Hugging Face Hubと組み合わせて研究と実装をつないでいます。PEFT・Accelerator・TRLなど周辺ライブラリの中核として、自前運用のLLM基盤を組む際の中心的な道具になっています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント